力扣题目解析 题目涉及到的解法以标签的形式注解
但请注意, 解法不唯一, 所有解析只提供一种解法, 以期抛转引玉
举一反三, 与君共勉
This is the multi-page printable view of this section. Click here to print.
力扣题目解析 题目涉及到的解法以标签的形式注解
但请注意, 解法不唯一, 所有解析只提供一种解法, 以期抛转引玉
举一反三, 与君共勉
给定一个长度为 n 的整数数组 height 。有 n 条垂线,第 i 条线的两个端点是 (i, 0) 和 (i, height[i]) 。
找出其中的两条线,使得它们与 x 轴共同构成的容器可以容纳最多的水。
返回容器可以储存的最大水量。
**说明:**你不能倾斜容器。
中等


流程如上, 核心算法是 贪心
配合双指针找到最大面积并不断更新
贪心的判断是较大的长度为边界, 不断迭代小的边界来贪心寻找最大面积
最后返回
class Solution {
public int maxArea(int[] height) {
//初始化指针
int left = 0;
int right = height.length - 1;
//面积
int maxSize = 0;
while(left < right){
maxSize = Math.max(maxSize, Math.min(height[left], height[right]) * (right - left));
// 移动指针
if (height[left] <= height[right]) {
left++; // 增大左边的指针
} else {
right--; // 减小右边的指针
}
}
return maxSize;
}
}
给定一个整数数组 nums 和一个整数目标值 target,请你在该数组中找出 和为目标值 target 的那 两个 整数,并返回它们的数组下标。
你可以假设每种输入只会对应一个答案,并且你不能使用两次相同的元素。
你可以按任意顺序返回答案。
中等

我们可以用双指针遍历两遍数组
for(int add = 0; add < length; add++){
for(int pair = add + 1; pair < length; pair++ ){
if(nums[add] +nums[pair] == target){
int[] result = new int[]{add, pair};
return result;
}
}
}
但是复杂度达到 O(n^2), 运行时间会很长

主要耗时的步骤在查找数组上, 在第二次循环中我们重复查找了一些元素 可以把元素放入哈希表中, 减少查询复杂度
简单建个模

class Solution {
public int[] twoSum(int[] nums, int target) {
//但是遍历数组的方法太麻烦, 我们换用查找复杂度为 O1 的哈希
//哈希表存储当前索引和预期值
HashMap<Integer, Integer> map = new HashMap<>();
int length = nums.length;
for(int value = 0; value < length; value++){
//补数, 我们根据补数来查找索引
int completement = target - nums[value];
//先查找是否存在, 存在就直接返回
//匹配
if(map.containsKey(completement)){
int[] result = new int[]{value, map.get(completement)};
return result;
}
//不存在, 放入map里面
map.put(nums[value], value);
}
return null;
}
}
给你一个字符串数组,请你将 字母异位词 组合在一起。可以按任意顺序返回结果列表。
字母异位词 是由重新排列源单词的所有字母得到的一个新单词。
中等
输入: strs = ["eat", "tea", "tan", "ate", "nat", "bat"]
输出: [“bat”],[“nat”,“tan”],[“ate”,“eat”,“tea”]
String 排序 String 中可以转为 Array 数组, 根据比较器实现自然排序
方法为 sort();

流程如上, 解释一下
对于数组的每一个元素, 转为 Array 数组并调用排序方法排序 在哈希表中做快速查询, 哈希表存储 有序数组和原数组集合, 返回原数组集合即可
import java.util.*;
public class Solution {
public List<List<String>> groupAnagrams(String[] strs) {
// 哈希表存储排序后的字符串作为键,异位词作为值
Map<String, List<String>> map = new HashMap<>();
for (String s : strs) {
// 将字符串转换为字符数组并排序
char[] chars = s.toCharArray();
Arrays.sort(chars);
// 排序后的字符数组作为键
String sortedStr = new String(chars);
// 如果该键不存在,初始化一个新的列表
map.putIfAbsent(sortedStr, new ArrayList<>());
// 将原始字符串加入到对应的列表中
map.get(sortedStr).add(s);
}
// 返回所有的异位词组
return new ArrayList<>(map.values());
}
}
给你一个二叉树的根节点 root , 检查它是否轴对称。
简单
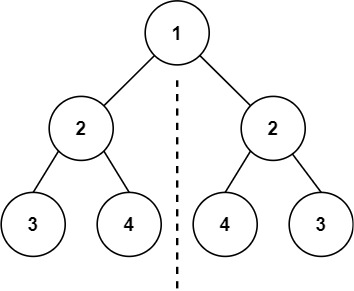
输入:root = [1,2,2,3,4,4,3] 输出:true
递归检查子树即可, 要求每一层的左右子树必须一致
先写辅助的递归, 在递归中检查左右子树是否一致, 也就是每一层左右节点是否相等
public boolean isMirror(TreeNode r1, TreeNode r2){
//第一出口, 左右节点同时为NULL
if(r1 == null && r2 == null){
return true;
}
//如果两个节点不同时为空, 代表左右两颗树层数不一致
if(r1 == null || r2 == null){
return false;
}
//递归体, 检查该层节点以及子树是否相等
return (r1.val == r2.val) &&
ismirror(r1.left, r2.right) &&
ismirror(r2.left, r1.right);
}
首先传递, 当某一层节点为NULL是回归
一旦发现左右子树不一致就返回false, 并将错误回归
当左右子树同时传递完成, 代表层数一致, 检查节点数值
之后按照对称性, 传递
左节点的左子树, 右节点的右子树;
右节点的左子树和左节点的右子树
给定一个二叉树 root ,返回其最大深度。
二叉树的 最大深度 是指从根节点到最远叶子节点的最长路径上的节点数。
简单

此题就是经典的遍历
那么二叉树有两种遍历, BFS.DFS 我们选择DFS
DFS使用递归实现深度遍历 我们编写递归函数
public int search(TreeNode root){
//递归
//归条件
if(root == null){
return 0;
}
//递右节点
int left = search(root.left);
//递右节点
int right = search(root.right);
//归条件
return (right >= left) ? right + 1 : left + 1;
}
递归体中, 不断向下遍历子节点 第一个出口, 节点为零时回归 第二个出口, 子节点变量完成
选择左右两支中最深的返回即可
初始化窗口:设置两个指针,通常是 left 和 right,它们表示窗口的左右边界。起初,窗口可以是一个空窗口或者包含一部分元素。
扩展窗口:通过移动 right 指针,扩展窗口的范围,使其包含更多的元素。
收缩窗口:当窗口中的元素不满足某个条件时(例如元素数量超过一定值,或者元素的某些属性不满足要求),就移动 left 指针,缩小窗口的范围。
更新结果:每次当窗口符合条件时,更新结果或记录窗口的位置。
给定两个字符串 s 和 p,找到 s 中所有 p 的 异位词 的子串,返回这些子串的起始索引。不考虑答案输出的顺序。
中等

第一次尝试, 想到了滑动窗口 对目标字符串排序, 排成有序字符数组 然后在窗口截取子串, 再把子串排序 匹配, 返回窗口左边界

想法很简单, 但是这里有两个问题
每一个子串都要排序, 复杂度是 
这和滑动窗口的理念不符, 滑动窗口是动态确定包含的元素的, 这种方法和迭代没区别
第二次尝试, 改进滑动窗口
给你一个正整数 n ,生成一个包含 1 到 n2 所有元素,且元素按顺时针顺序螺旋排列的 n x n 正方形矩阵 matrix 。
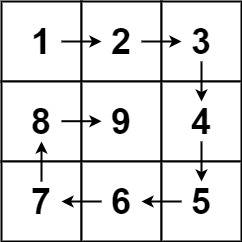
输入:n = 3 输出:[1,2,3],[8,9,4],[7,6,5]
中等
class Solution {
public int[][] generateMatrix(int n) {
// 正确初始化二维数组
int[][] matrix = new int[n][n];
// 定义四个边界
int left = 0;
int right = n - 1;
int top = 0;
int bottom = n - 1;
// 数字从1开始填充
int num = 1;
while (num <= n * n) {
// 从左到右填充上边界
for (int i = left; i <= right; i++) {
matrix[top][i] = num++;
}
top++;
// 从上到下填充右边界
for (int i = top; i <= bottom; i++) {
matrix[i][right] = num++;
}
right--;
// 从右到左填充下边界
for (int i = right; i >= left; i--) {
matrix[bottom][i] = num++;
}
bottom--;
// 从下到上填充左边界
for (int i = bottom; i >= top; i--) {
matrix[i][left] = num++;
}
left++;
}
return matrix;
}
}
贪心算法 (Greedy Algorithm) 是一种求解优化问题的算法策略,它在求解问题的每一步选择中都做出当前看来最优的选择,而不考虑后续可能带来的影响。贪心算法的核心思想是 局部最优解 和 全局最优解。
贪心算法的特点
给你一个非负整数数组 nums ,你最初位于数组的 第一个下标 。数组中的每个元素代表你在该位置可以跳跃的最大长度。
判断你是否能够到达最后一个下标,如果可以,返回 true ;否则,返回 false 。
中等

求路径是否可以抵达可以使用贪心算法 我们维持一个最远路径, 迭代器迭代节点时更新最远路径, 判断是否可达即可

这里要在迭代前判断该时代是否可达, 迭代器的迭代可不会自动判断节点是否可达
class Solution {
public boolean canJump(int[] nums) {
//最远位置, 最一开始是0
int maxHeap = 0;
//指向贪心节点的指针
int pos = 0;
//长度, 循环终止条件
int length = nums.length;
//极限情况
if(length == 0 || length == 1){
return true;
}
//迭代器
for(; pos < length; ++pos){
//拿节点
int node = nums[pos];
//判断节点是否可达
if(maxHeap < pos){
//该世代无法抵达
return false;
}
//更新最远位置
maxHeap = Math.max(maxHeap, nums[pos] + pos);
//判断是否已经可以到达终点
if(maxHeap >= length - 1){
return true;
}
}
//循环结束没有结果
return false;
}
}
#### 题意:
给你一个长度为 n 的链表,每个节点包含一个额外增加的随机指针 random ,该指针可以指向链表中的任何节点或空节点。
构造这个链表的 深拷贝。 深拷贝应该正好由 n 个 全新 节点组成,其中每个新节点的值都设为其对应的原节点的值。新节点的 next 指针和 random 指针也都应指向复制链表中的新节点,并使原链表和复制链表中的这些指针能够表示相同的链表状态。复制链表中的指针都不应指向原链表中的节点 。
例如,如果原链表中有 X 和 Y 两个节点,其中 X.random --> Y 。那么在复制链表中对应的两个节点 x 和 y ,同样有 x.random --> y 。
返回复制链表的头节点。
用一个由 n 个节点组成的链表来表示输入/输出中的链表。每个节点用一个 [val, random_index] 表示:
val:一个表示 Node.val 的整数。random_index:随机指针指向的节点索引(范围从 0 到 n-1);如果不指向任何节点,则为 null 。你的代码 只 接受原链表的头节点 head 作为传入参数。
中等
和通常的深拷贝不同的是, 这里的节点多了随机指针
那么在拷贝随机指针之前, 就必须有原链表
因此分为三步
复制节点并插入原节点后面:
while (cur != null) {
Node newNode = new Node(cur.val);
newNode.next = cur.next;
cur.next = newNode;
cur = newNode.next;
}
比如原链表:A->B->C 变成 A->A’->B->B’->C->C'
复制随机指针:
while (cur != null) {
if (cur.random != null) {
cur.next.random = cur.random.next;
}
cur = cur.next.next;
}
利用第一步创建的节点关系,设置复制节点的random指针:
分离两个链表:
while (cur != null) {
Node next = cur.next.next;
Node copy = cur.next;
copyCur.next = copy;
copyCur = copy;
cur.next = next;
cur = next;
}
将交织在一起的链表分开:
class Solution {
public Node copyRandomList(Node head) {
if (head == null) {
return null;
}
// 第一步:在每个原节点后创建一个新节点
Node cur = head;
while (cur != null) {
Node newNode = new Node(cur.val);
newNode.next = cur.next;
cur.next = newNode;
cur = newNode.next;
}
// 第二步:处理random指针
cur = head;
while (cur != null) {
if (cur.random != null) {
cur.next.random = cur.random.next;
}
cur = cur.next.next;
}
// 第三步:分离两个链表
Node dummy = new Node(0);
Node copyCur = dummy;
cur = head;
while (cur != null) {
// 保存下一个原始节点
Node next = cur.next.next;
// 复制的节点
Node copy = cur.next;
copyCur.next = copy;
copyCur = copy;
// 恢复原始链表
cur.next = next;
cur = next;
}
return dummy.next;
}
}
给你一个链表的头节点 head ,判断链表中是否有环。
如果链表中有某个节点,可以通过连续跟踪 next 指针再次到达,则链表中存在环。 为了表示给定链表中的环,评测系统内部使用整数 pos 来表示链表尾连接到链表中的位置(索引从 0 开始)。注意:pos 不作为参数进行传递 。仅仅是为了标识链表的实际情况。
如果链表中存在环 ,则返回 true 。 否则,返回 false 。
简单
示例 1:

输入:head = [3,2,0,-4], pos = 1 输出:true 解释:链表中有一个环,其尾部连接到第二个节点。
使用循环遍历链表查重的方法内存和时间开销很大
这里介绍一种算法, 龟兔赛跑算法, 就是快慢指针
定义两个指针, 二者遍历速度不同, 这样就可以保证快指针在有环的情况下可以追上慢指针
public class Solution {
public boolean hasCycle(ListNode head) {
if (head == null || head.next == null) {
return false;
}
ListNode slow = head;
ListNode fast = head.next;
while (slow != fast) {
if (fast == null || fast.next == null) {
return false;
}
slow = slow.next;
fast = fast.next.next;
}
return true;
}
}
给你两个单链表的头节点 headA 和 headB ,请你找出并返回两个单链表相交的起始节点。如果两个链表不存在相交节点,返回 null 。
图示两个链表在节点 c1 开始相交

题目数据 保证 整个链式结构中不存在环。
简单
示例 1:

输入:intersectVal = 8, listA = [4,1,8,4,5], listB = [5,6,1,8,4,5], skipA = 2, skipB = 3
输出:Intersected at ‘8’
判断相交在链表中是一项很基本, 也很重要的算法
我们可以将两个链表分别遍历并放入哈希表中去重, 但是当数组较长时会浪费许多资源
其实这道题的核心是找出第一个相交节点, 而非全部节点, 所以可以使用双指针同时遍历两个链表
大致思路如下:
public class Solution {
public ListNode getIntersectionNode(ListNode headA, ListNode headB) {// 定义两个指针,初始分别指向两个链表头部
// 如果任一链表为空,则不可能相交
if (headA == null || headB == null) {
return null;
}
ListNode ptrA = headA;
ListNode ptrB = headB;
// 当两个指针不相等时继续遍历
while (ptrA != ptrB) {
// 移动指针A
ptrA = ptrA == null ? headB : ptrA.next;
// 移动指针B
ptrB = ptrB == null ? headA : ptrB.next;
}
// 返回相交节点,如果不存在则返回null
return ptrA;
给你一个链表,删除链表的倒数第 n 个结点,并且返回链表的头结点。

输入:head = [1,2,3,4,5], n = 2 输出:[1,2,3,5]
中等
题目一共要求做两件事
对于单项链表, 如何找到节点的位置?
可以两次遍历, 第一次遍历拿链表长度
第二次才获取具体的节点
如何删除该节点?
删除节点涉及到三个部分
前驱节点, 该节点, 后驱节点
所以我们在第一步拿到前驱节点, 并保存后驱节点, 修改引用就算删除完毕
遍历链表
while (current != null) { length++; current = current.next; }
注意是倒数第 n 个节点,所以要用链表的长度减去 n。倒数第 4 个节点的前一个节点就是 5-4=1,也就是第一个节点。
class Solution {
public ListNode removeNthFromEnd(ListNode head, int n) {
// 创建一个虚拟头节点,简化边界条件处理
ListNode dummy = new ListNode(0);
dummy.next = head;
// 第一次遍历,计算链表的总长度
int length = 0;
ListNode current = head;
while (current != null) {
length++;
current = current.next;
}
// 设置长度为到达要删除的节点的前一个节点
int index = length - n;
current = dummy;
// 第二次遍历,找到要删除的节点的前一个节点
for (int i = 0; i < index; i++) {
current = current.next;
}
// 删除节点,即跳过要删除的节点
current.next = current.next.next;
return dummy.next;
}
}
翻转给定的链表

输入:head = [1,2,3,4,5] 输出:[5,4,3,2,1]
简单
链表翻转有两种方法
这里我们用迭代法
从图中可以看出, 对链表的翻转可以理解为箭头方向变化
这样我们可以讲链表转为两两一组的节点对, 从头开始迭代
对于节点对, 我们分为首节点和次节点, 在单向链表, 次节点指向其他节点, 一旦断开次节点的引用, 其他节点会丢失
所以需要提前存储其他节点
改变引用关系大致流程如下:
class Solution {
public ListNode reverseList(ListNode head) {
//迭代法
ListNode current = head;
ListNode previous = null;
while(current != null){
ListNode temp = current.next;
current.next = previous;
previous = current;
current = temp;
}
return previous;
}
}
将两个升序链表合并为一个新的 升序 链表并返回。新链表是通过拼接给定的两个链表的所有节点组成的。
简单

输入:l1 = [1,2,4], l2 = [1,3,4] 输出:[1,1,2,3,4,4]
提供的链表有序, 所以可以同时遍历. 连接较小的节点即可
class Solution {
public ListNode mergeTwoLists(ListNode l1, ListNode l2) {
// 创建哑节点作为合并后链表的头部
ListNode dummy = new ListNode(0);
ListNode current = dummy;
// 同时遍历两个链表,比较节点值
while (l1 != null && l2 != null) {
if (l1.val <= l2.val) {
current.next = l1;
l1 = l1.next;
} else {
current.next = l2;
l2 = l2.next;
}
current = current.next;
}
// 将剩余节点接到合并后的链表末尾
current.next = (l1 != null) ? l1 : l2;
return dummy.next;
}
}
给你一个链表数组,每个链表都已经按升序排列。
请你将所有链表合并到一个升序链表中,返回合并后的链表。

合并链表. 最容易想到的就是依次合并
首先合并 1,2 之后合并3 这样依次合并
如何合并?
因为所提供的链表都是有顺序的 所以采用双指针方式
但很遗憾,这样做的话,每一次合并后的新链表就会非常臃肿,并且在与第 K 个链表合并时,之前链表的节点会多次被访问。
我们可以使用分治的思想解决
为了解决臃肿和重复遍历的问题, 把链表的整体合并转为两两合并链表的子问题

首先判空
if (lists == null || lists.length == 0) {
return null;
}
设置间隔, 每次只对间隔的头结点做合并操作
int interval = 1; // 初始间隔为1
while (interval < n) { // 当间隔小于链表总数时继续循环
这里使用interval来控制合并的步长,比如:
合并
for (int i = 0; i < n - interval; i += interval * 2) {
lists[i] = merge2Lists(lists[i], lists[i + interval]);
}
合并逻辑
while (l1 != null && l2 != null) {
if (l1.val <= l2.val) {
current.next = l1;
l1 = l1.next;
} else {
current.next = l2;
l2 = l2.next;
}
current = current.next;
}
//处理剩余节点
current.next = (l1 != null) ? l1 : l2;
整体如下:
class Solution {
public ListNode mergeKLists(ListNode[] lists) {
if (lists == null || lists.length == 0) {
return null;
}
int n = lists.length;
int interval = 1;
while (interval < n) {
for (int i = 0; i < n - interval; i += interval * 2) {
lists[i] = merge2Lists(lists[i], lists[i + interval]);
}
interval *= 2;
}
return lists[0];
}
private ListNode merge2Lists(ListNode l1, ListNode l2) {
// 创建哑节点作为合并后链表的头部
ListNode dummy = new ListNode(0);
ListNode current = dummy;
// 同时遍历两个链表,比较节点值
while (l1 != null && l2 != null) {
if (l1.val <= l2.val) {
current.next = l1;
l1 = l1.next;
} else {
current.next = l2;
l2 = l2.next;
}
current = current.next;
}
// 将剩余节点接到合并后的链表末尾
current.next = (l1 != null) ? l1 : l2;
return dummy.next;
}
}
给你一个链表,两两交换其中相邻的节点,并返回交换后链表的头节点。 你必须在不修改节点内部的值的情况下完成本题(即,只能进行节点交换)。
中等

输入:head = [1,2,3,4] 输出:[2,1,4,3]
看到这道题,我们要先搞清楚什么是两两交换,比如 1->2->3->4,交换后就是 2->1->4->3。
第一个和第二个交换,第三个和第四个交换,以此类推。
那么就可以把整个链转为子链, 通过递归处理
/**
* Definition for singly-linked list.
* public class ListNode {
* int val;
* ListNode next;
* ListNode() {}
* ListNode(int val) { this.val = val; }
* ListNode(int val, ListNode next) { this.val = val; this.next = next; }
* }
*/
class Solution {
public ListNode swapPairs(ListNode head) {
return swapAndConnect(head);
}
public ListNode swapAndConnect(ListNode node) {
if (node == null || node.next == null) {
// 如果当前节点或下一个节点为空,直接返回当前节点
return node;
}
// 递归:获取后面的交换结果
ListNode partner = node.next;
ListNode next = swapAndConnect(partner.next);
// 交换当前节点和下一个节点
node.next = next;
partner.next = node;
// 返回交换后的新头节点
return partner;
}
}
/**
* Definition for singly-linked list.
* public class ListNode {
* int val;
* ListNode next;
* ListNode() {}
* ListNode(int val) { this.val = val; }
* ListNode(int val, ListNode next) { this.val = val; this.next = next; }
* }
*/
class Solution {
public ListNode reverseKGroup(ListNode head, int k) {
// 基本判断
if (head == null || k == 1) return head;
// 计算当前组的长度是否够k个节点
ListNode curr = head;
int count = 0;
while (curr != null && count < k) {
curr = curr.next;
count++;
}
// 如果不够k个节点,保持原有顺序
if (count < k) return head;
// 递归处理后续节点组
curr = reverseKGroup(curr, k);
// 翻转当前组的k个节点
ListNode prev = curr;
ListNode now = head;
while (count > 0) {
ListNode next = now.next;
now.next = prev;
prev = now;
now = next;
count--;
}
return prev;
}
}