Introduce
Input and output not same length
decided by model itself which is called Seq2Seq Model

Seq2Seq Model structure
Encoder and Decoder
Transformer is a enhanced S2S model
Encoder

Encoder in Transformer

Not a layer, is multi-layer

Decoder
called Autoregressive

Introduce one of two decoder - Autoregressive decoder
Decoder is generate result
there has a way make seq as input
result will contain a dictionary, with soft-max find MOST value(Classification)

next character will based on current character

What if Error propagation?
How model decide output length?
we need a special input ‘stop’
NAT
result is not generate one and another
result have same length as BEGIN

for example, In voice recognition, slow speed though add more BEGIN
While NAT is usually worse than AT
PUTTOGETHER

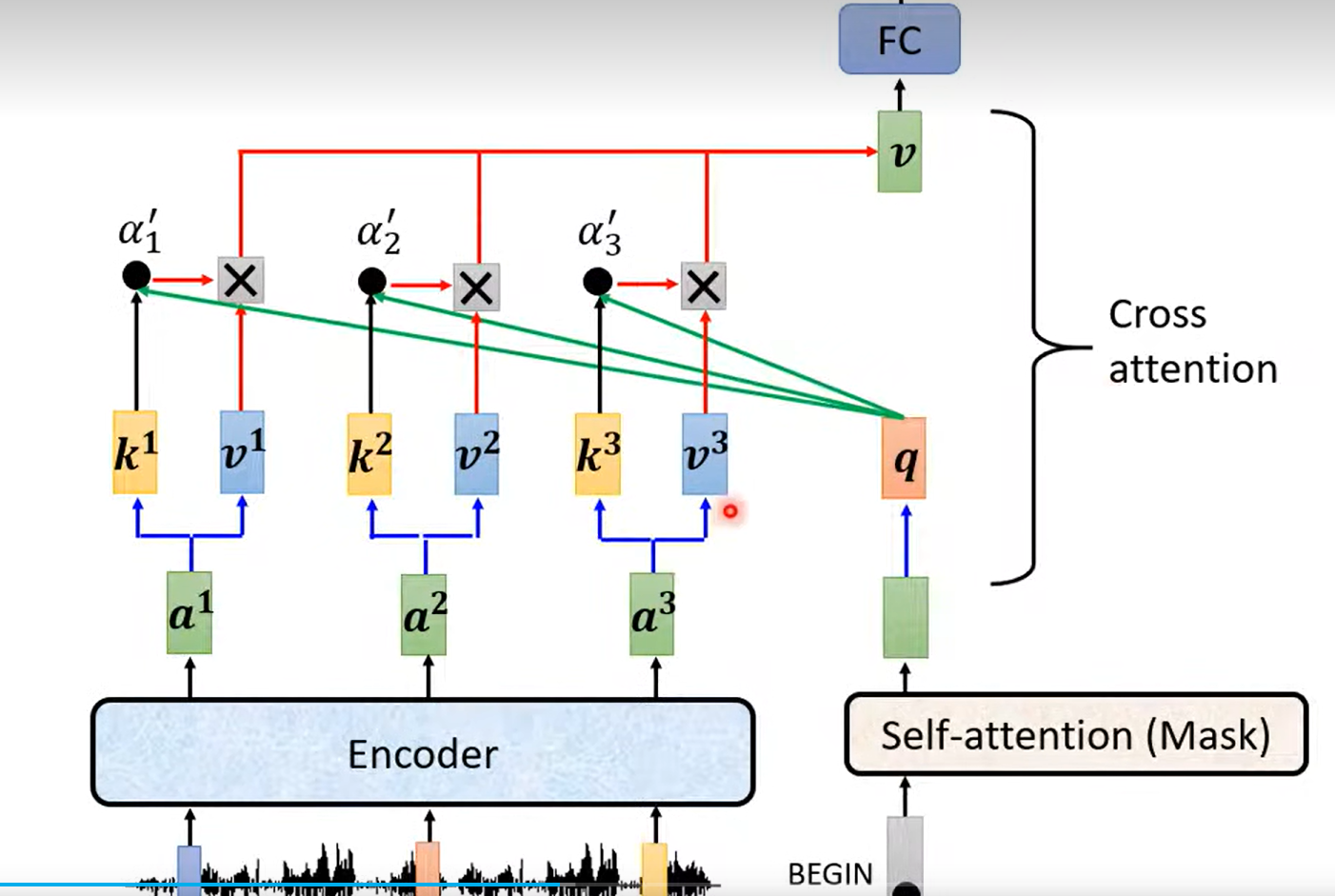
CROSS-ATTENTION
Feedback
Was this page helpful?
Glad to hear it! Please tell us how we can improve.
Sorry to hear that. Please tell us how we can improve.