This is the multi-page printable view of this section. Click here to print.
MachineLearning
- 1: DINOv2
- 2:
- 3:
- 4:
1 - DINOv2
目錄
- ViT
- DINO
- DINOv2 3.1 論文與原理 3.2 代碼簡單分析
- sd-DINO 4.1 論文與原理 4.2. 代碼簡單分析
- 總結
ViT
*Transformer 在圖像上的拓展
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
===A neural network architecture that’s revolutionized natural language processing (NLP) and is now being used in various other fields like computer vision and audio generation==. –wikipedia
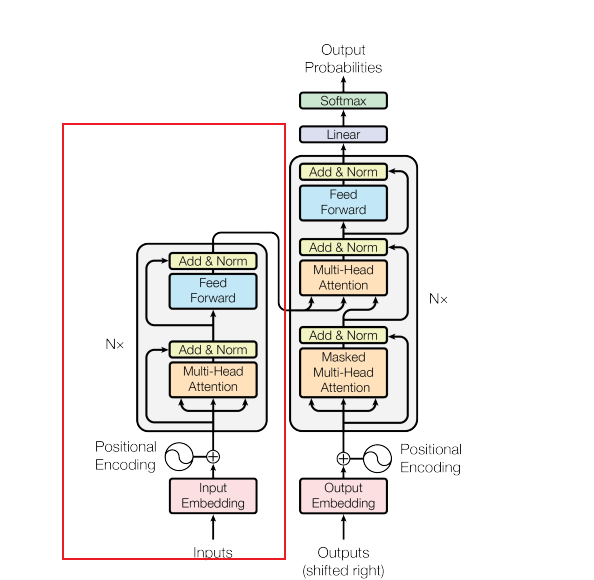
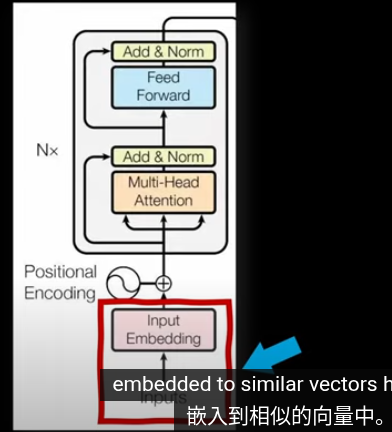
經典的Transformer
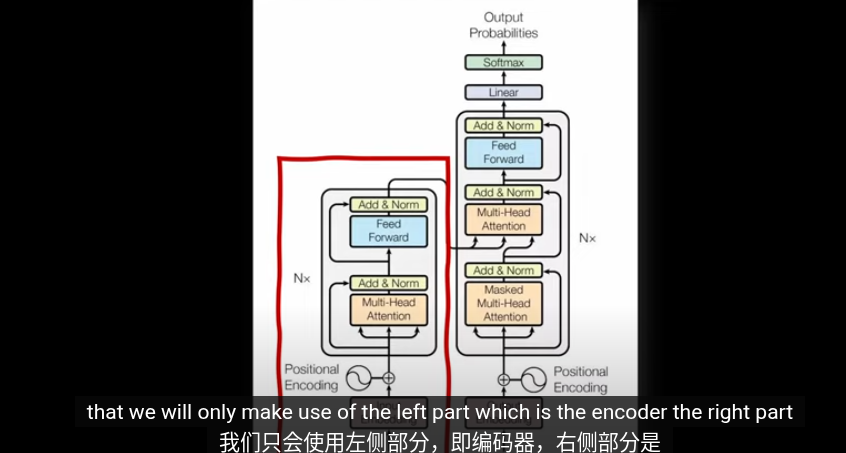
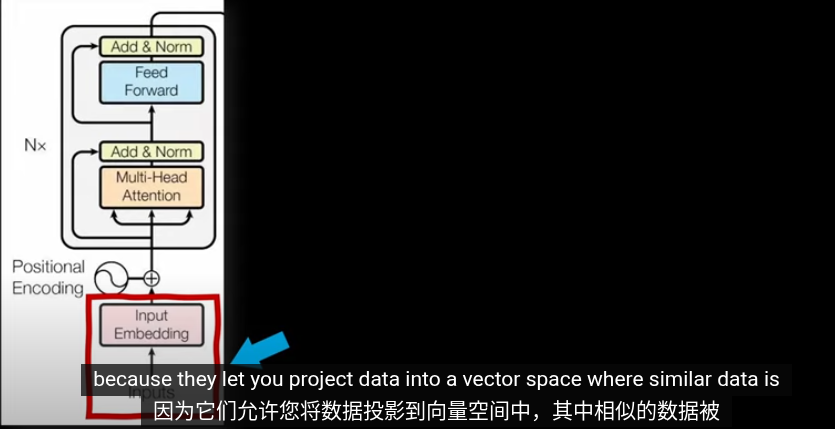
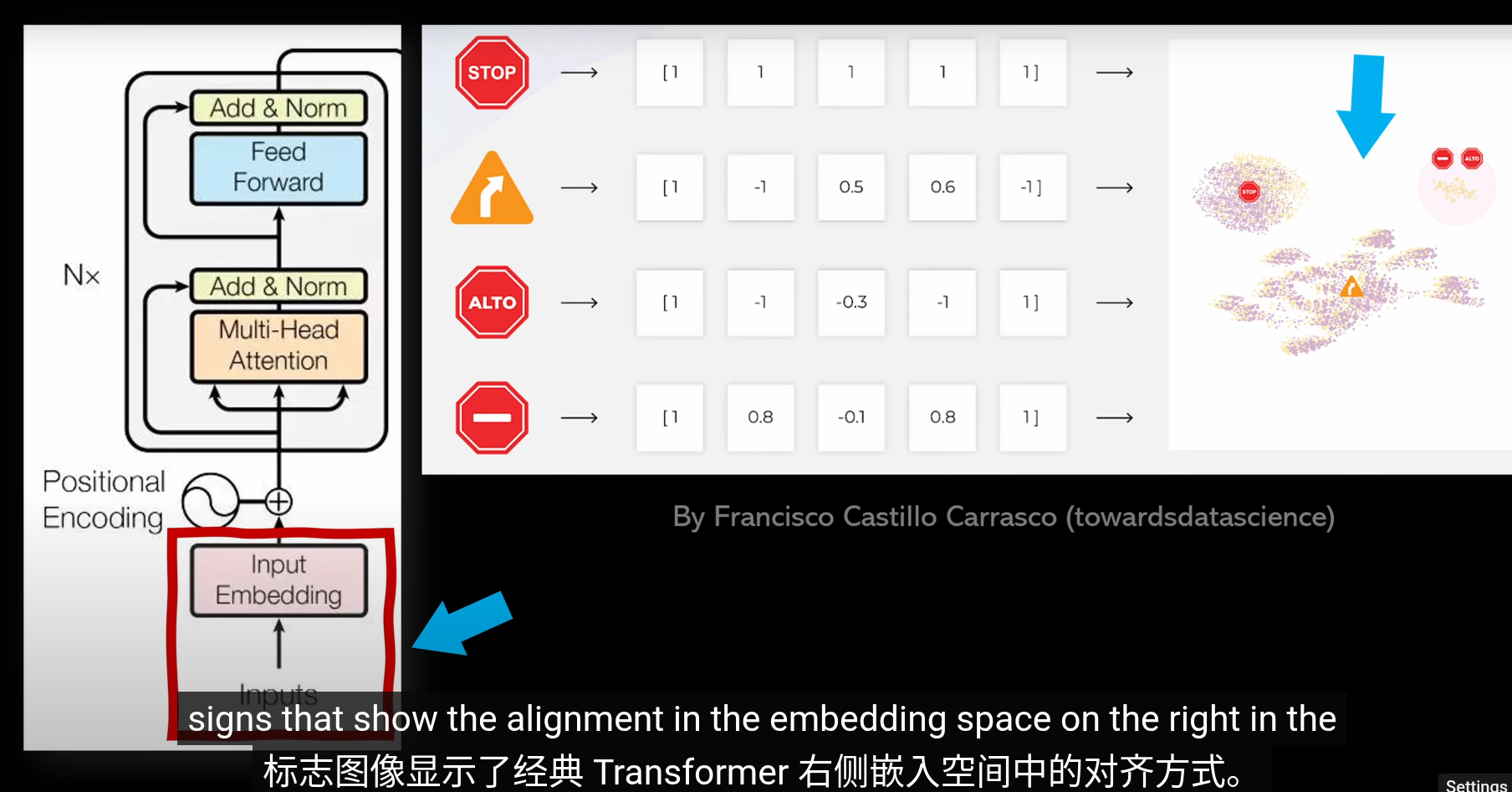
Transformer分爲兩部分,左側編碼層用於將數據(Token)投影到向量空間,其中相似的數據會投影到相似的向量。右側用於生成任務(GPT預測下一個詞)我們主要關注左側的編碼部分
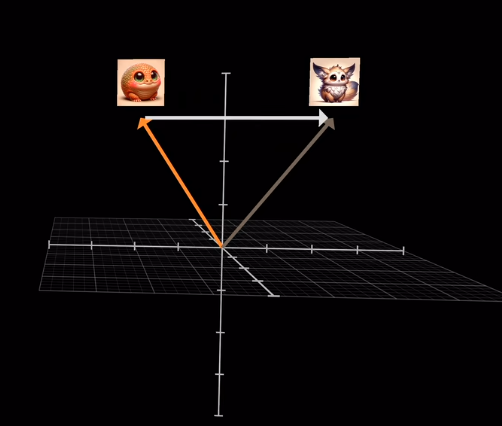
經典Transformer中的示例,語義特徵相似的圖片方向相似(不是ViT)
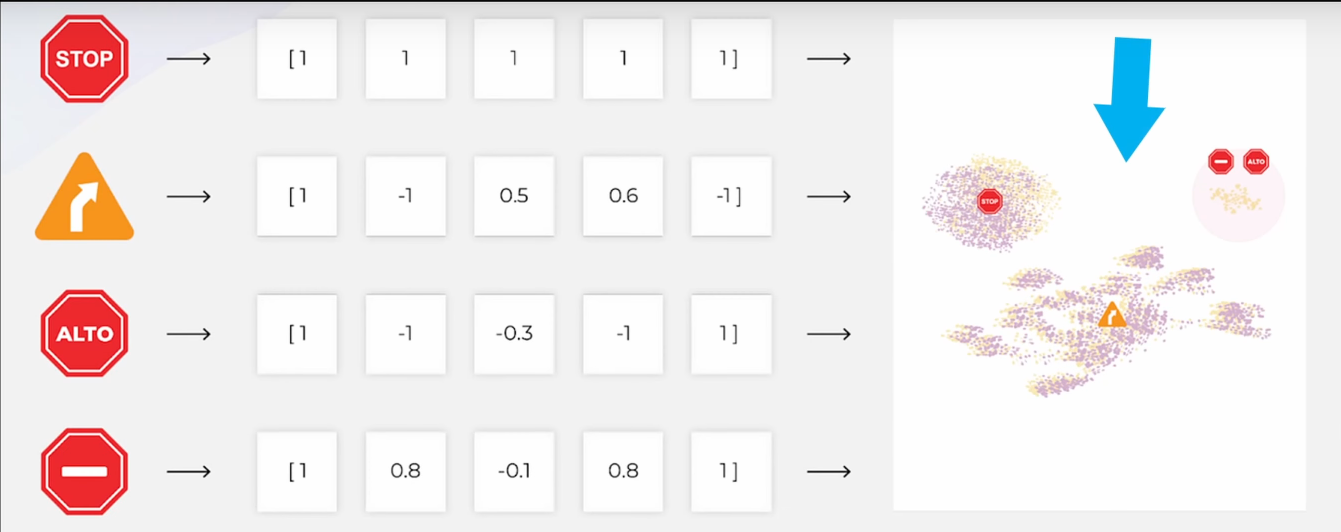
嵌入可視化 左側是不同的交通標誌(如 STOP、ALTO、禁止進入、右轉等),每個圖像被編碼成一組特徵向量,- STOP 與 ALTO(西語“停止”)以及禁止進入標誌聚集在一起,右轉標誌則落在另一個明顯不同的區域。
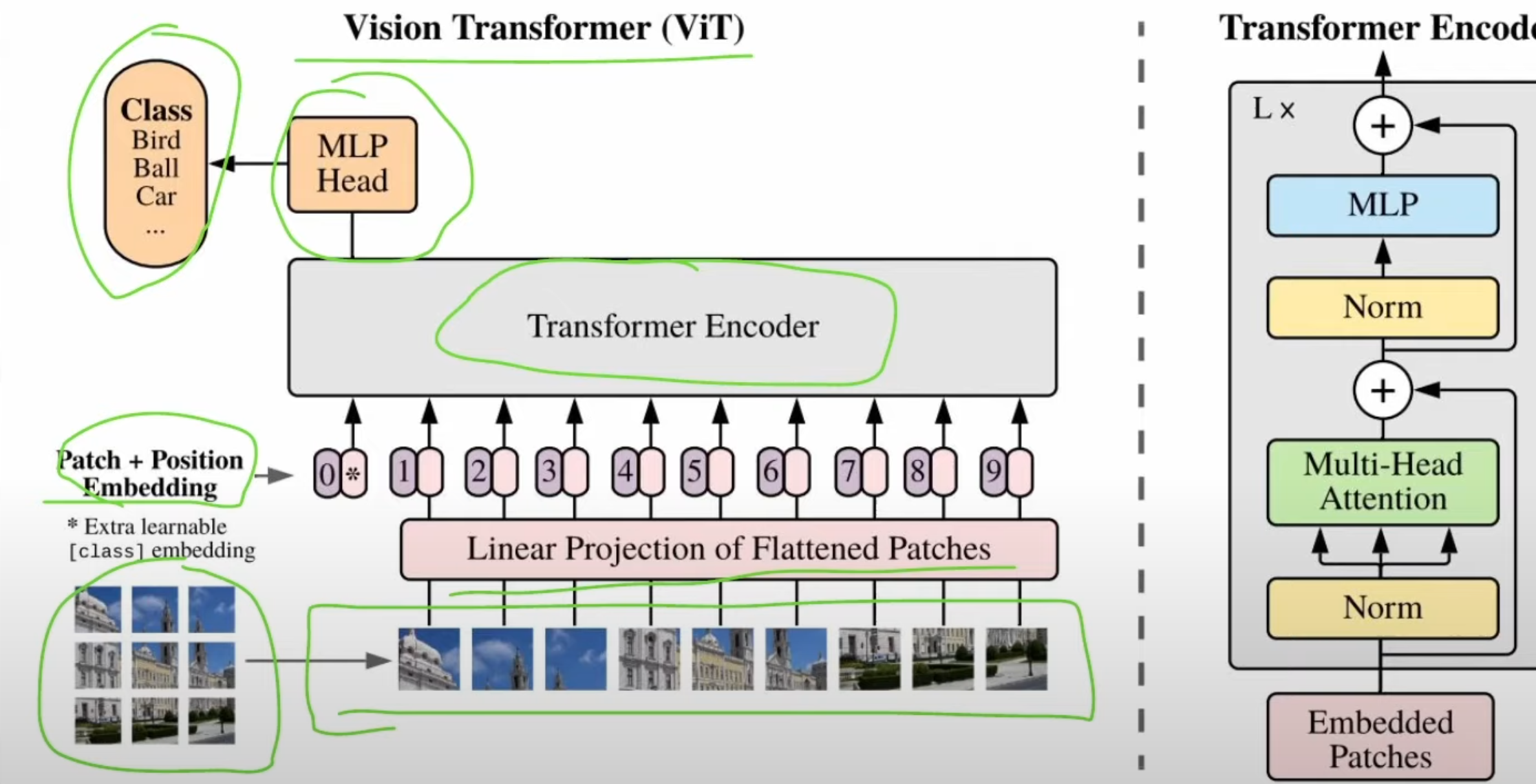
Vision Transformer 是 Transformer 對圖像數據的拓展。相較與 CNN,ViT 是基於自注意力的架構 (Self-attention-based architectures)。
Vision Transformer(ViT)結構上與自然語言處理中的 Transformer 類似,其核心是將圖像切分為固定大小的 patch,嵌入為向量後加入位置編碼,經過多層 Transformer 模塊進行特徵建模。ViT 將圖像轉換為高維特徵空間中的一組表示,使得這些特徵在該空間中具有結構化或可分性,便於後續分類等下游任務。這些高維特徵不直接對應語義單元,而是作為模型輸出語義預測的中間表徵。
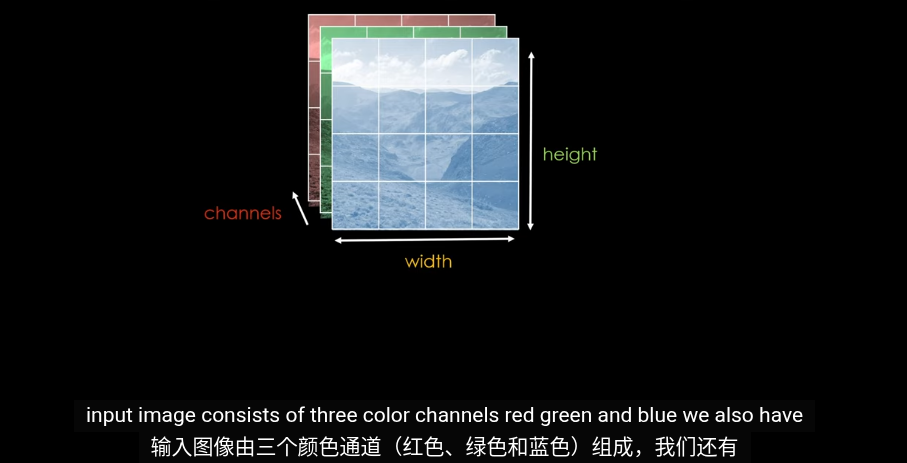
NLP中的Token是通過拆分句子爲詞組得到的,在圖像中這是由圖像補丁(Patch)得到的

一張圖片
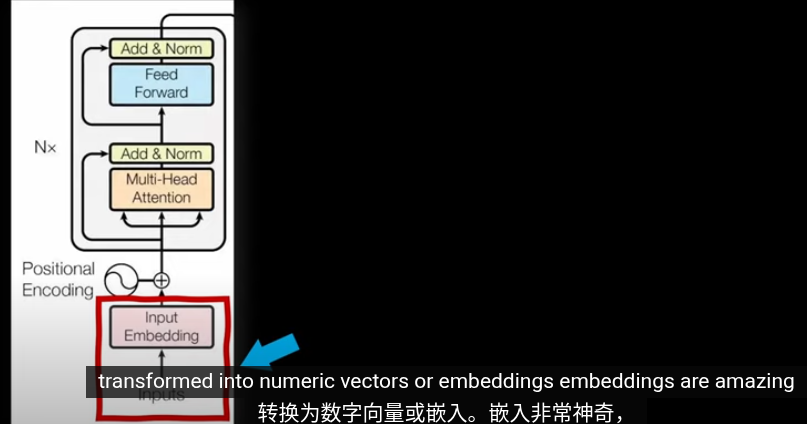
輸入的圖像是由三個顏色通道RGB,以及寬和高組成。將一張圖片拆成大小相同的小塊就可以作爲Token輸入到編碼器中。編碼器會對每個patch生成嵌入(Embedding)由於拆分圖像時會失去位置信息,所以在施加注意力前(Attention)需要加上位置向量
在 Vision Transformer (ViT) 中,位置編碼採用可學習的位置嵌入(learnable positional embeddings),為每個圖像 patch 和 CLS Token 分配一個獨特的向量,表示其在圖像中的空間位置。ViT 的可學習嵌入能通過訓練適應圖像的 2D 空間結構,提供靈活的位置信息。這些嵌入與 patch 特徵一起輸入 Transformer,幫助注意力機制捕捉 patch 之間的空間關係。CLS Token 作為一個特殊的標記,利用位置嵌入的上下文,通過多層注意力機制聚合所有 patch 的特徵,生成用於下游任務(如分類)的全局表示
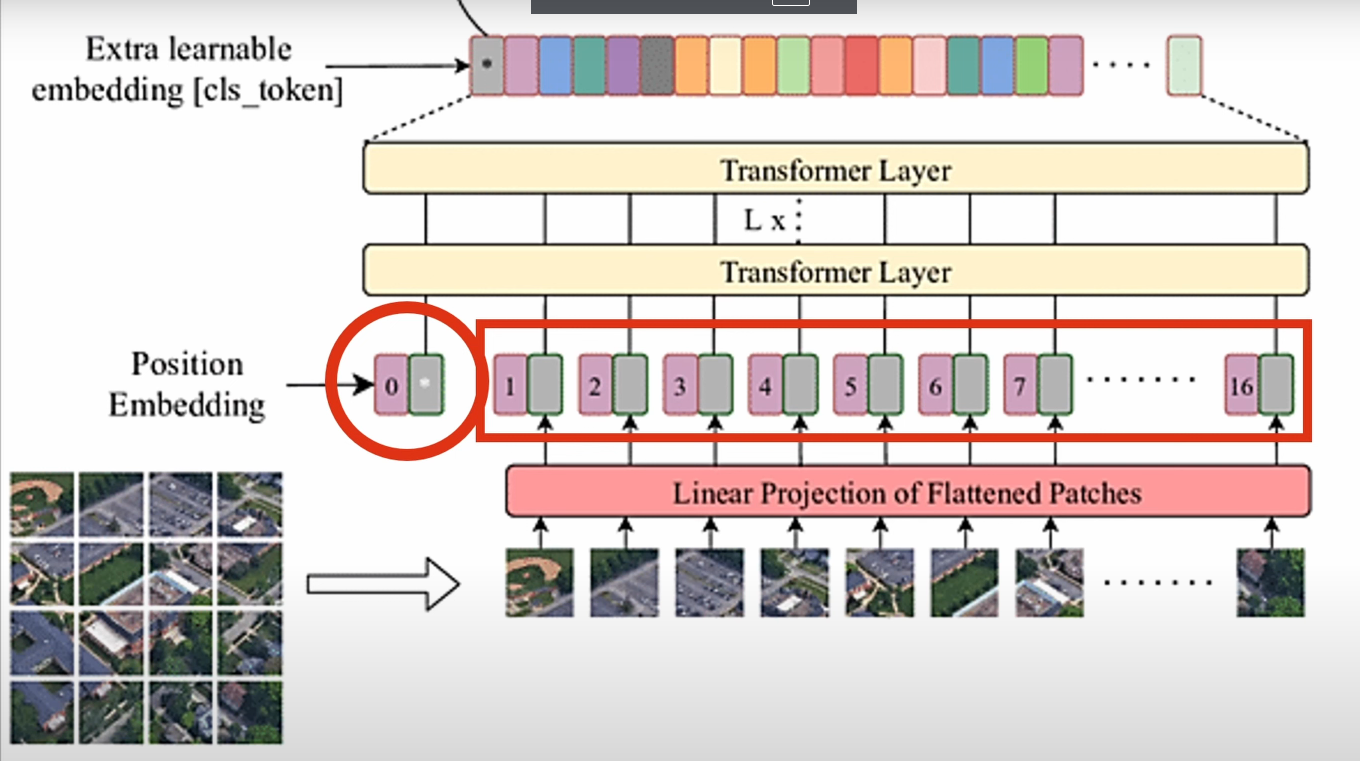
ViT 架構
Embedding 經過多個Transformer layer層後(基本上是許多注意力層,前向層交替)後經過歸一化得到高維特徵。
許多細節此處忽略,,比如學習不同patch之間輸入距離的函數,殘差和跳躍鏈接。這些內容和主題相差甚遠此處忽略 ViT Video on Youtube
在加上分類頭後(MLP頭爲例)可以輸出類別
DINO
一種新的基於 ViT自監督訓練方法 Emerging Properties in Self-Supervised Vision Transformers
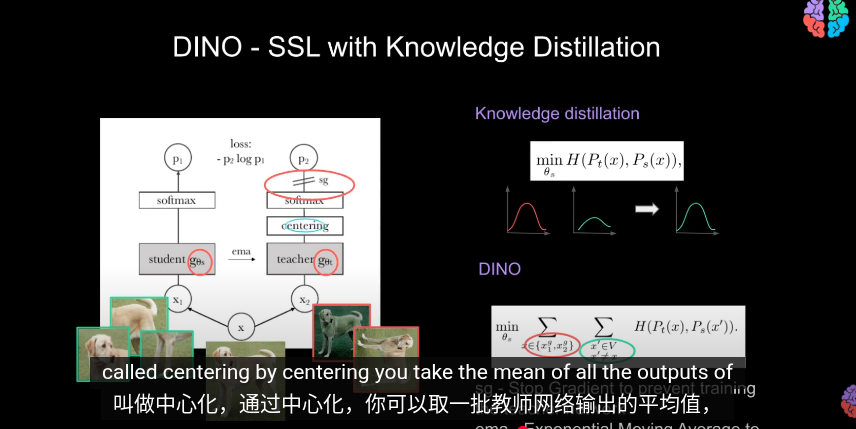
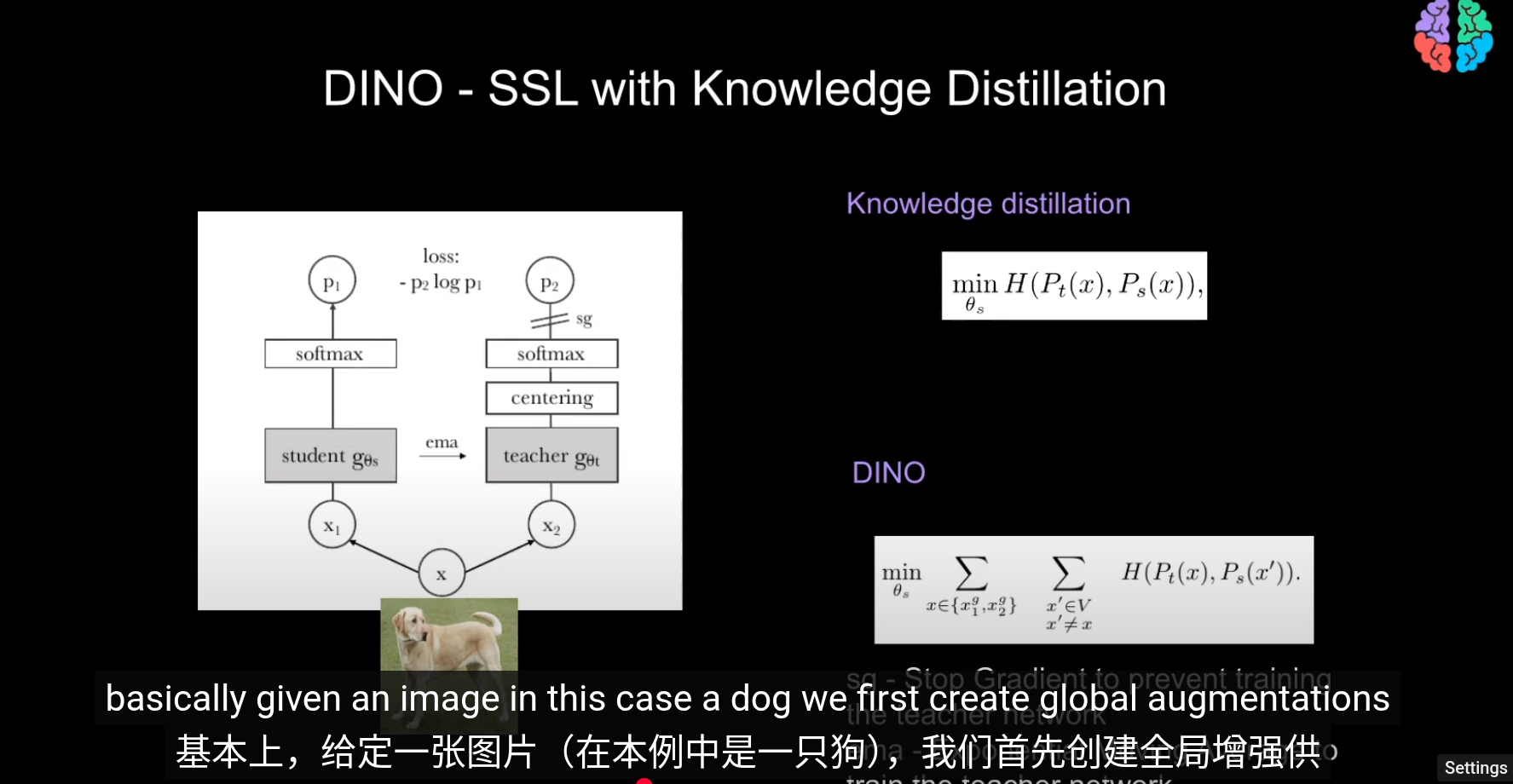
DINO模型實際上只是對ViT的一個包裝,實現了自蒸餾(知識蒸餾的一種)
知識蒸餾(Knowladge distillation)
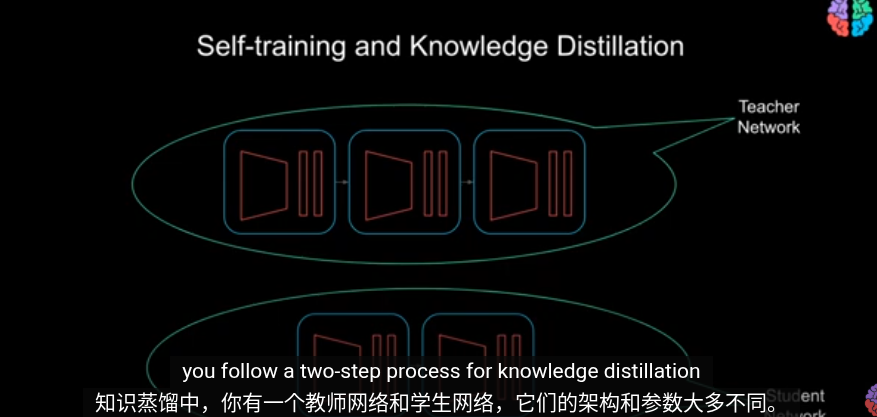
先說知識蒸餾,知識蒸餾的目的是爲了壓縮模型,節省計算資源。也就是訓練一個小型模型來模擬大型模型的輸出,兩個模型從架構到參數都有細微區別。
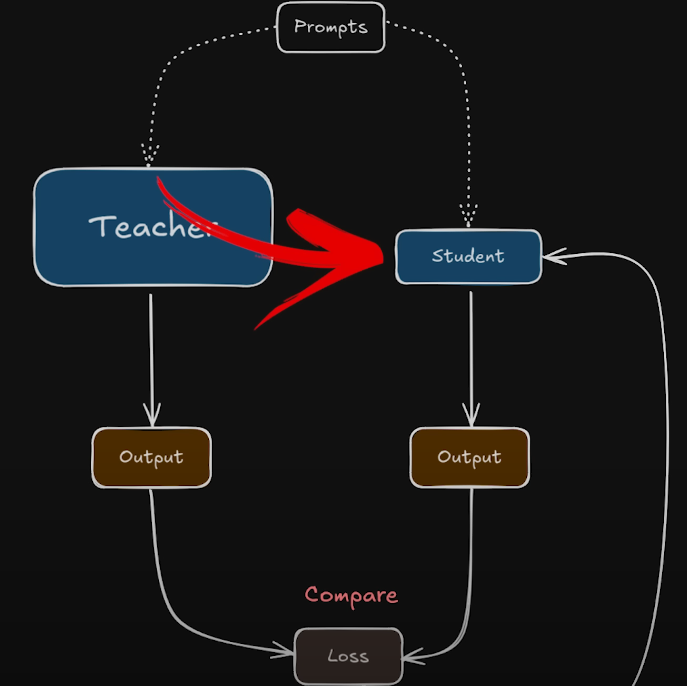
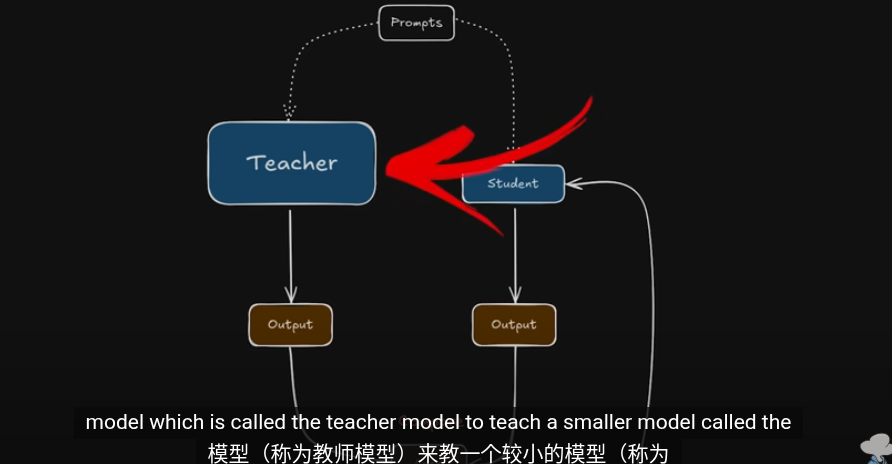
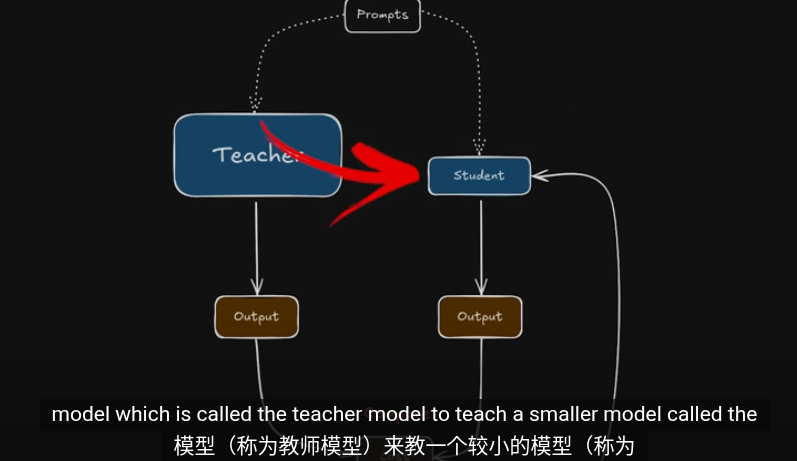
簡單的教師學生蒸餾模型
Self-training aims at improving the quality of features by propagating a small initial set of annotations to a large set of unlabeled instances. This ==propagation== can either be done with hard assignments of labels or with a soft assignment . When using ==soft labels==, the approach is often referred to as ==knowledge distillation== – 2104.14294
知識蒸餾流程
我們已經擁有訓練好的大模型(teacher)以及標籤數據集
我們讓student同時訓練標籤(硬標籤)以及教師在無標籤數據集上的概率分佈(僞標籤/軟標籤)我們的目的是$$
訓練一個學生網絡 gθs 去模仿一個教師網絡 gθt 的輸出。
$$
其中s是學生參數,t是教師參數
對於輸入的圖像x,pt和ps分別是教師和學生網絡在高維空間的概率分佈(softmax)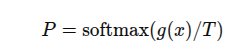 其中T是softmax的溫度,控制平滑程度的
對於已經給定的教師t,使用 損失函數(交叉熵),最小化交叉熵來訓練學生網絡的參數s,儘量是學生的輸出分佈和教師一致
其中T是softmax的溫度,控制平滑程度的
對於已經給定的教師t,使用 損失函數(交叉熵),最小化交叉熵來訓練學生網絡的參數s,儘量是學生的輸出分佈和教師一致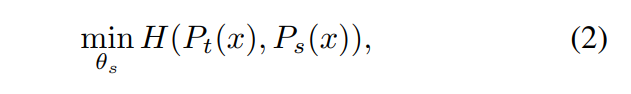
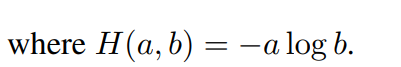
但我們希望無需任何標籤實現自監督學習,這就是DINO的目的
DINO 英文來自於 Self-==DI==stillation with ==NO== lable
DINO的核心思想如下
-
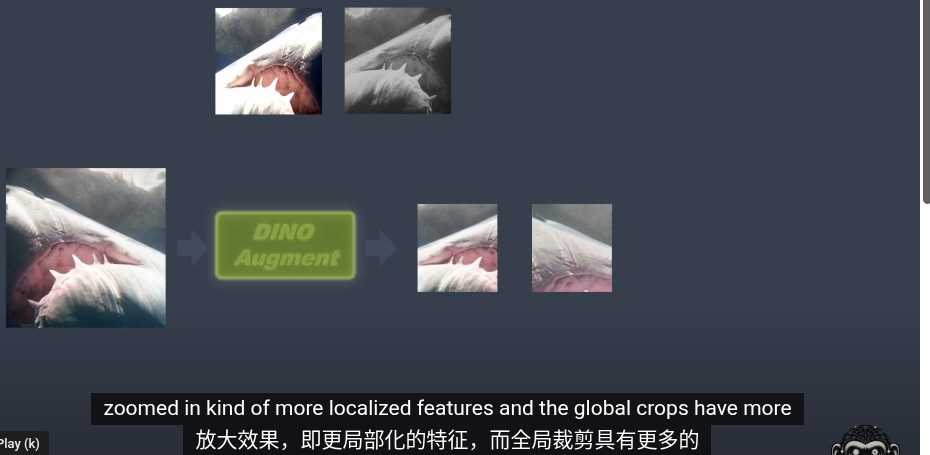
給一張圖片進行兩種不同的數據增強(
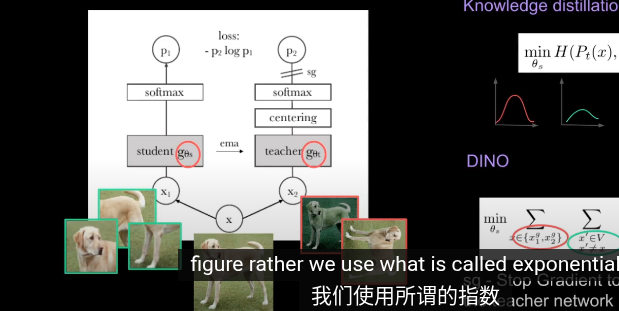
augment)稱全局裁剪和局部裁剪 从给定图像生成一个由不同视图组成的集合 V。该集合包含两个全局视图 (globe crop)x1g 和 x2g 以及几个分辨率较低的局部视图(local crop)(一般8個)。所有裁剪图像都经过学生模型,而只有全局视图经过老师模型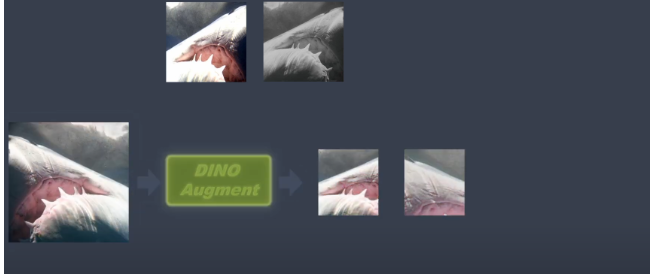
-
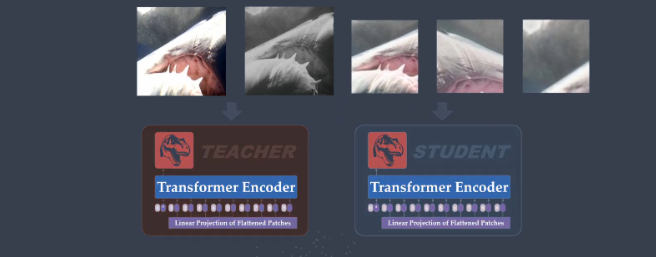
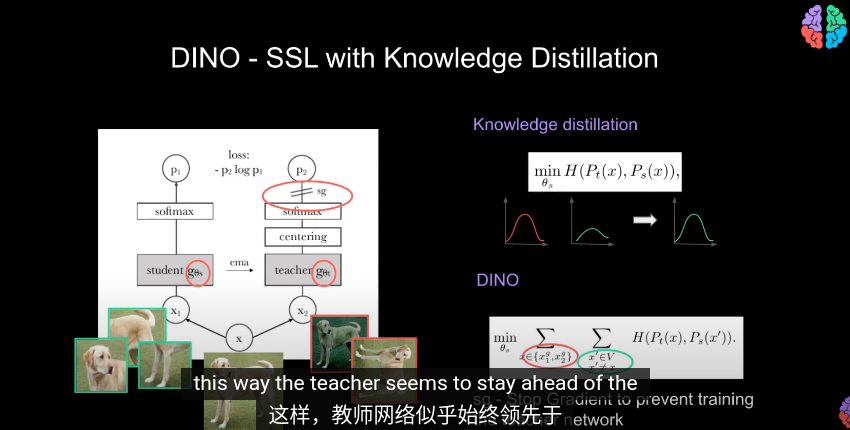
用student網絡來學習,並用teacher網絡產生教學信號 不需要標籤,學習的目的是讓 student 的輸出在不同增強下與 teacher 對齊 和知識蒸餾不同的是,這裏教師隨學生一起訓練, 在訓練時動態構建, teacher可以看做是學生的一個副本。 輸入的局部和全局裁剪經過兩個網絡以及softmax後輸出概率分佈(共65532個類)比較教師和學生的輸出,其中教師在輸出softmax概率前會做中心化,教師的輸出叫教學信號。這裏的輸出可以類比latent space,圖像特徵潛空間
 由於輸入是局部和全局的裁剪,我們訓練目標是找到==局部到全局==的對應或者說讓模型知道那些的圖片一樣那些不一樣(判別式方法:通常指直接建模條件概率 𝑃 ( 𝑦 ∣ 𝑥 ) ,即給定輸入 𝑥 x,預測輸出 𝑦 的概率。這裏是給定圖像 𝑥 ,預測其增強版本的特徵或偽標籤分佈。)
我們鼓勵局部到全局的對應。和知識蒸餾類似我們使用修改過的交叉熵損失函數求最小值(隨機梯度下降)从给定图像生成一个由不同视图组成的集合 V。该集合包含两个全局视图和局部試圖
由於輸入是局部和全局的裁剪,我們訓練目標是找到==局部到全局==的對應或者說讓模型知道那些的圖片一樣那些不一樣(判別式方法:通常指直接建模條件概率 𝑃 ( 𝑦 ∣ 𝑥 ) ,即給定輸入 𝑥 x,預測輸出 𝑦 的概率。這裏是給定圖像 𝑥 ,預測其增強版本的特徵或偽標籤分佈。)
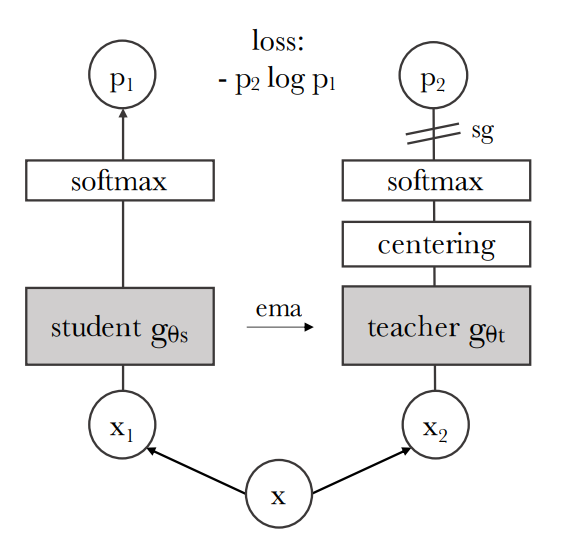
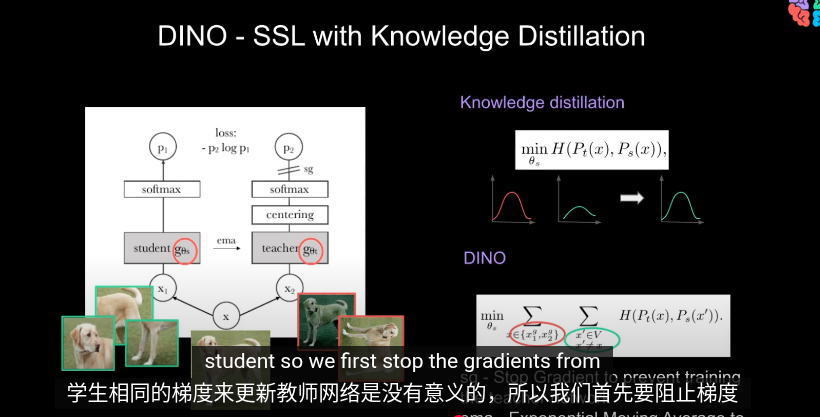
我們鼓勵局部到全局的對應。和知識蒸餾類似我們使用修改過的交叉熵損失函數求最小值(隨機梯度下降)从给定图像生成一个由不同视图组成的集合 V。该集合包含两个全局视图和局部試圖 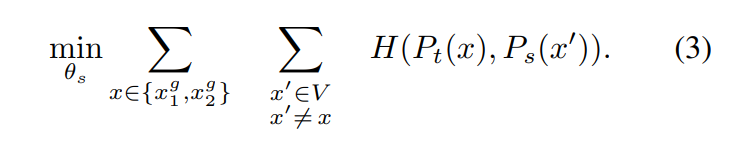 其實,對於教師網絡和學生網絡同時做梯度下降求最小值沒有任何意義。我們的目標是讓學生模仿教師,而不是互相調整所以這裏使用參數sg阻止梯度更新轉而使用 EMA 指數平均線/動量平均值(股票的K線)來更新網絡。根據學生的過去迭代來動態構建教師網絡
在每個梯度更新中,只有學生 student 是唯一需要學習的網絡,教師只是學生的指數移動平均線(副本)
其實,對於教師網絡和學生網絡同時做梯度下降求最小值沒有任何意義。我們的目標是讓學生模仿教師,而不是互相調整所以這裏使用參數sg阻止梯度更新轉而使用 EMA 指數平均線/動量平均值(股票的K線)來更新網絡。根據學生的過去迭代來動態構建教師網絡
在每個梯度更新中,只有學生 student 是唯一需要學習的網絡,教師只是學生的指數移動平均線(副本)
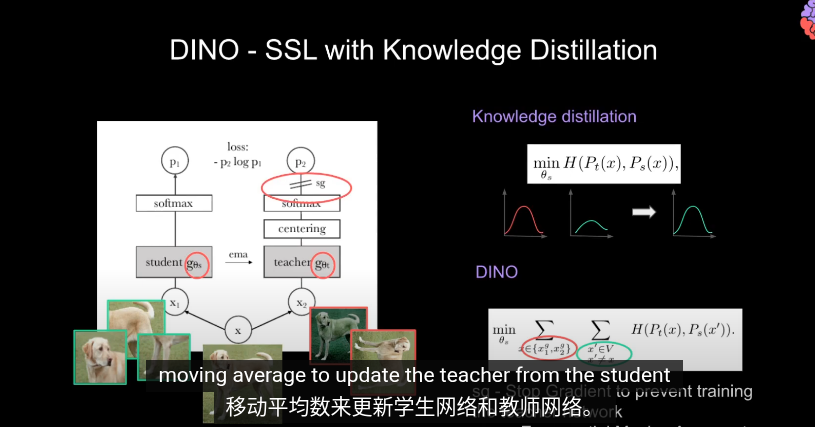
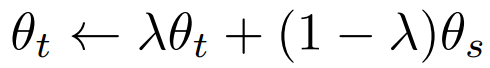 指數移動平均(Exponential Moving Average, EMA)公式,目的是用來更新教師網絡(teacher network) 的參數 θt,讓它平滑地追蹤學生網絡(student network)的參數 θs,其 中lamda是溫度,用於控制學生參數佔比也就是教師更新參數的平滑程度,默認0.992
因此經過 EMA, 中心化,阻止教師的梯度加上學生的參數後教師可以認爲是==學生的一個更穩定的版本==(正則化)這樣,教師網絡就能領先與學生網絡並產生教學信號引導學生訓練。
指數移動平均(Exponential Moving Average, EMA)公式,目的是用來更新教師網絡(teacher network) 的參數 θt,讓它平滑地追蹤學生網絡(student network)的參數 θs,其 中lamda是溫度,用於控制學生參數佔比也就是教師更新參數的平滑程度,默認0.992
因此經過 EMA, 中心化,阻止教師的梯度加上學生的參數後教師可以認爲是==學生的一個更穩定的版本==(正則化)這樣,教師網絡就能領先與學生網絡並產生教學信號引導學生訓練。
核心算法(僞代碼)
gt.params = gs.params # 初始化 teacher 為 student 的拷貝,兩者是一模一樣的
for x in loader: # 對於每個 batch
x1, x2 = augment(x), augment(x) # 同一張圖的兩個不同增強版本
s1, s2 = gs(x1), gs(x2) # student 對增強圖像的輸出 (n x K)
t1, t2 = gt(x1), gt(x2) # teacher 的輸出 (n x K)
# 計算對稱損失,讓 s1 對齊 t2,s2 對齊 t1
loss = H(t1, s2)/2 + H(t2, s1)/2
loss.backward() # 反向傳播
update(gs) # 使用 SGD 更新 student 參數
# Momentum 更新 teacher 參數(無反向傳播)
gt.params = l*gt.params + (1-l)*gs.params #學生佔比很低 0.008
# 更新中心向量(用於 teacher 輸出的穩定化與對齊)
C = m*C + (1-m)*cat([t1, t2]).mean(dim=0)
總而言之,DINO本質上是對ViT進行的封裝,核心架構依舊是ViT但利用共蒸餾改進了訓練方法。DINO關注的是如何訓練ViT,本質是一種訓練方法
DINOv2
基於ViT的大規模預訓練圖像特徵生成基礎模型 Learning Robust Visual Features without Supervision
自然语言处理领域近期在海量数据模型预训练方面取得的突破,为计算机视觉领域类似的基础模型开辟了道路。这些模型可以生成通用的视觉特征(即无需微调即可跨图像分布和任务发挥作用的特征),从而大大简化图像在任何系统中的使用。
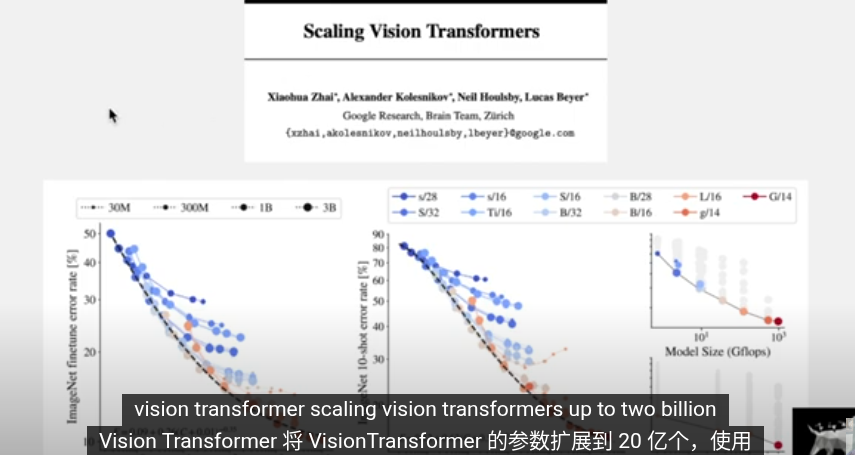
NLP在擴大訓練規模後可以得到高質量穩定的特徵,DINOv2希望通過類似的思路可以的到高==質量的圖像特徵==。 DINOv2 在DINO的基礎上擴大了訓練規模,其大多数技术贡献旨在加速和稳定大规模训练。

擴大訓練規模的效果
DINOv2爲了擴大與穩定訓練規模做了以下改進
-
精選數據集(automatic pipeline) 對於生成通用視覺特徵的目標,自監督學習在小型精選數據集上取得了進展,但當使用大量非精選的數據訓練時出現了特徵質量下降。这是因为缺乏对数据质量和多样性的控制,而这两者对于生成良好的特征至关重要。 爲此數據處理會自動精選圖像。来自精选和非精选数据源的图像首先被映射到嵌入向量。然后,非精选图像会进行去重,再与精选图像进行匹配。最终的组合通过自监督检索系统扩充了初始数据集。
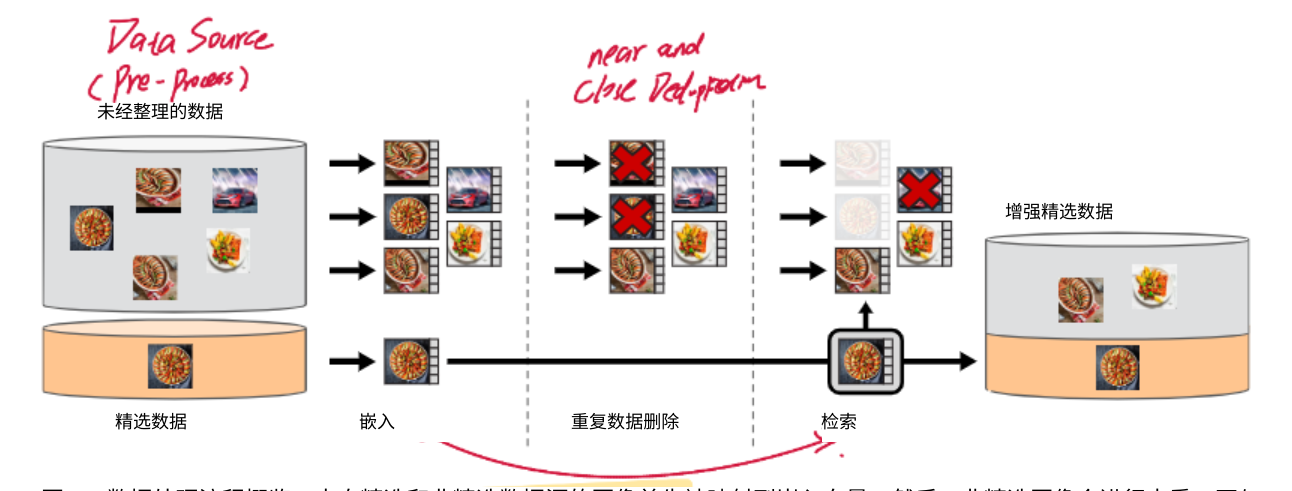
數據庫:首先,我们从公开的爬取网页数据存储库中收集了原始的、未经过滤的图片数据集。進行去重(PCA哈希去重、NSFW 过滤以及可识别人脸模糊处理)。收集到的所有圖像會作爲未精選數據集。和精選的數據集(Imagenet,google)一同進入embedding編碼環節
編碼:使用在 ImageNet-22k 上预训练的自监督 ViT-H/16 网络计算图像嵌入,并使用==余弦相 似度==作为图像之间的距离度量。計算相似度是爲了刪除相似圖片。(Deduplication) 由於我們並不清楚蒐集來的數據內容是什麼,如果含大量貓的圖片那麼模型可能只會得到貓的 特徵(數據偏奇/泛化不足)
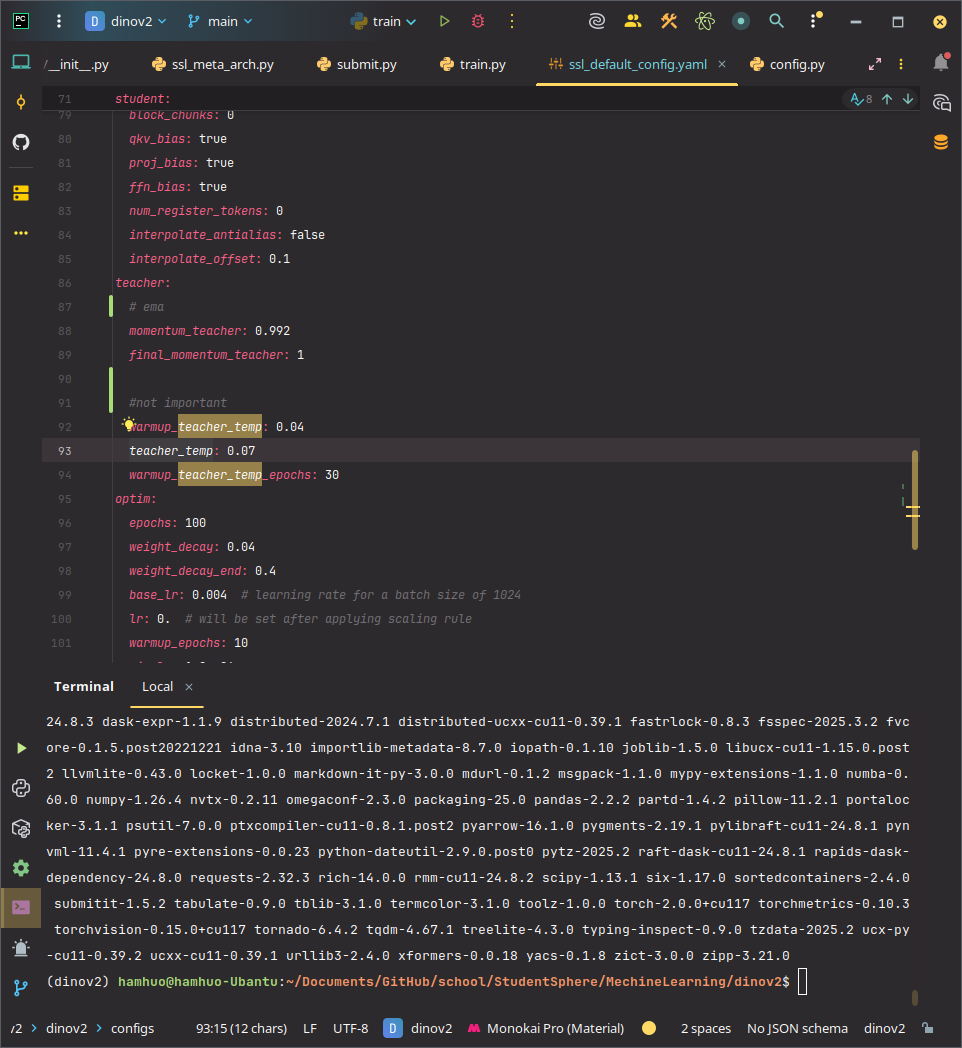
使用聚類可以有效解決,我们对未整理的数据执行 ==K 均值聚类==,分爲若干個語義相近的群。
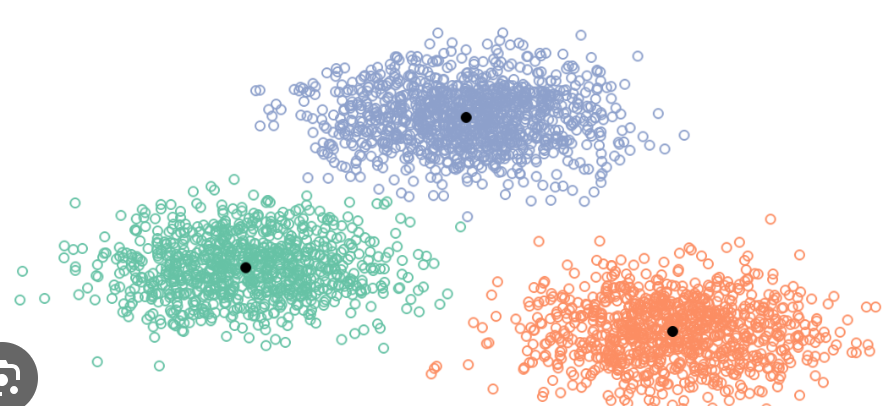 假設你有一批查詢圖片(想找與它們類似的圖片),對於每張查詢圖片,去整個資料庫中找「最接近的 N 張圖」,N 通常設為 4。
如果 N 設太大,檢索的圖片會出現「同一張圖片被多個查詢圖片檢索到」,造成重複,這種情況稱為==碰撞(collision)==。檢索後的圖片會合查詢圖片一起組合爲精選數據集
假設你有一批查詢圖片(想找與它們類似的圖片),對於每張查詢圖片,去整個資料庫中找「最接近的 N 張圖」,N 通常設為 4。
如果 N 設太大,檢索的圖片會出現「同一張圖片被多個查詢圖片檢索到」,造成重複,這種情況稱為==碰撞(collision)==。檢索後的圖片會合查詢圖片一起組合爲精選數據集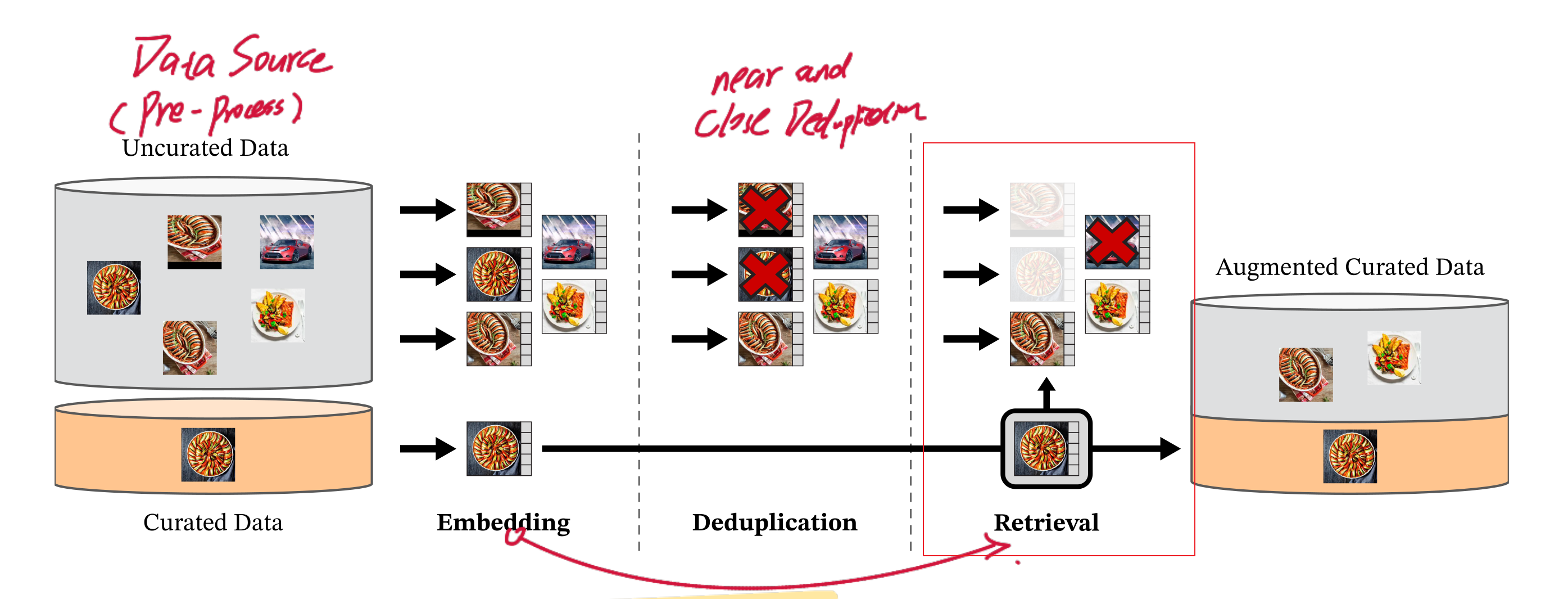
-
組合DINO 损失和 iBOT 损失(iBOT負責遮罩,patch級別的圖像特徵損失。 DINO負責整體圖像的特徵損失)
-
并以 SwAV 做中心化(Centering)。添加了一个正则化项来扩展特征(KoLeo 損失:正則化 CLS 標記,增強表示多樣性)
==最後兩項很複雜,我看不懂。這裏跳過==
代碼部分(DINOv2/DINO)
DINO的倉庫更新到DINOv2了,所以在這裏一起講
原始的 DINO倉庫,第一行建議重定向到 DINOv2
以下是位於 train.py 的訓練主循環(精簡版)
# DINOv2 訓練主循環:通過學生-教師架構進行自監督學習
# 目標:讓學生模型學習教師模型的圖像表示,無需標籤
for data in metric_logger.log_every(data_loader, 10, "Training", max_iter, start_iter):
# 從資料載入器獲取預處理的圖像批次(包含全局和局部裁剪)
current_batch_size = data["collated_global_crops"].shape[0] / 2
# 動態調整學習率和教師模型參數(如動量和溫度)
lr = lr_schedule[iteration] # 學習率
mom = momentum_schedule[iteration] # 教師模型的動量
teacher_temp = teacher_temp_schedule[iteration] # 教師模型的softmax溫度
# 前向傳播:學生模型和教師模型處理圖像,計算損失
# 損失包括 DINO 對比損失(匹配學生-教師輸出)和 iBOT 遮罩重建損失
loss_dict = model.forward_backward(data, teacher_temp=teacher_temp)
# 更新學生模型參數,根據損失調整權重
optimizer.step()
# 使用指數移動平均 (EMA) 更新教師模型,使其平滑跟隨學生模型
model.update_teacher(mom)
# 處理損失值(例如平均化),用於監控訓練進度
# loss_dict_reduced = {k: v.item() / distributed.get_global_size() for k, v in loss_dict.items()}
# 迭代計數器加 1,進入下一次迭代
iteration += 1
其中的前項和損失計算代碼如下(精簡)
def forward_backward(self, images, teacher_temp):
# 提取全局裁剪(global crops)和局部裁剪(local crops)圖像
global_crops = images["collated_global_crops"].cuda() # 兩張大視圖,全局
local_crops = images["collated_local_crops"].cuda() # 多張小視圖,局部
masks = images["collated_masks"].cuda() # 遮罩,用於 iBOT 損失
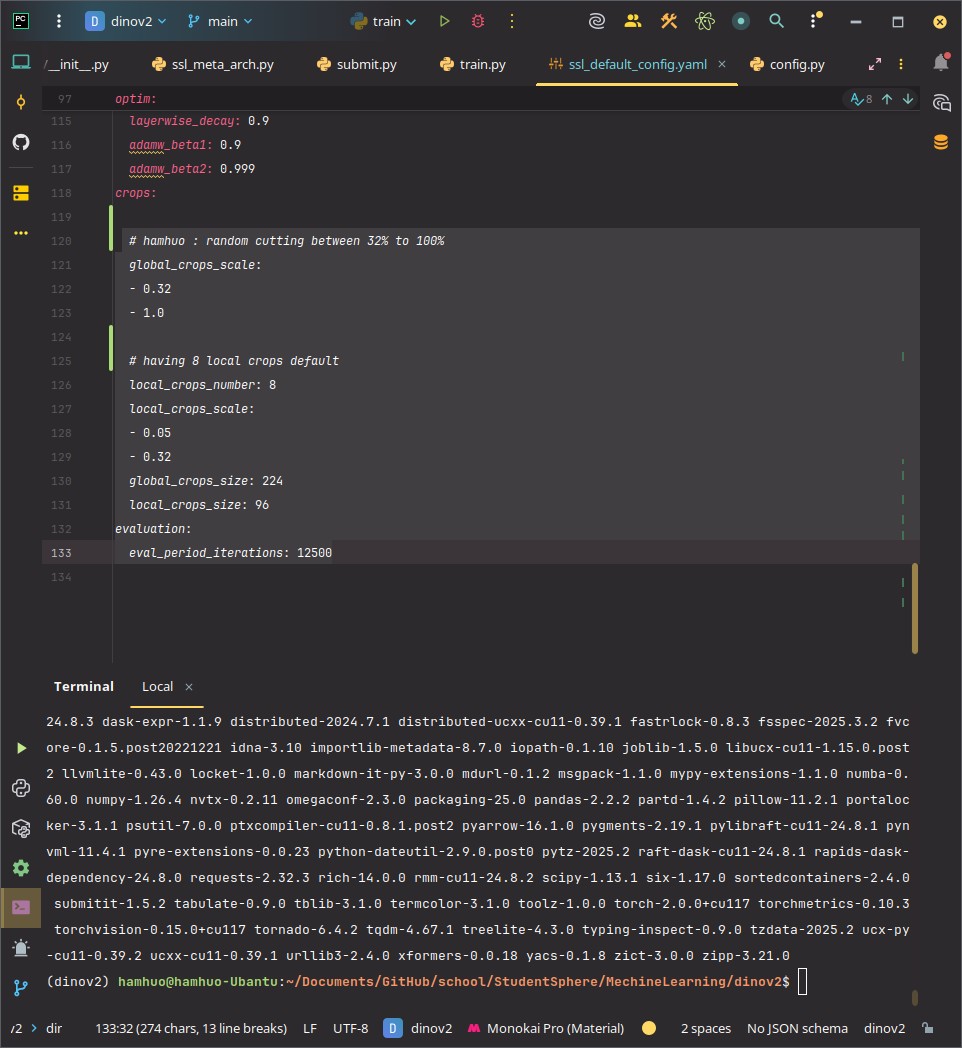
# 教師模型前向傳播(無梯度):處理全局裁剪,生成參考輸出
with torch.no_grad():
teacher_output = self.teacher.backbone(global_crops, is_training=True)
teacher_cls_tokens = teacher_output["x_norm_clstoken"] # CLS 標記,用於 DINO 損失。可以看作全局特徵提取器
teacher_patch_tokens = teacher_output["x_norm_patchtokens"] # Patch 標記,用於 iBOT 損失
# 對教師輸出應用 中心化和softmax概率,準備損失計算
teacher_cls_tokens = self.dino_loss.softmax_center_teacher(teacher_cls_tokens, teacher_temp)
teacher_patch_tokens = self.ibot_patch_loss.softmax_center_teacher(teacher_patch_tokens, teacher_temp)
# 學生模型前向傳播:處理全局和局部裁剪,生成預測
student_output = self.student.backbone([global_crops, local_crops], masks=[masks, None], is_training=True)
student_global_cls = student_output[0]["x_norm_clstoken"] # 全局裁剪的 CLS 標記
student_local_cls = student_output[1]["x_norm_clstoken"] # 局部裁剪的 CLS 標記
student_patch_tokens = student_output[0]["x_norm_patchtokens"] # 全局裁剪的 Patch 標記
# 初始化損失字典和累積器
loss_dict = {}
total_loss = 0
# 計算 DINO 損失:讓學生模型的 CLS 標記匹配教師模型的 CLS 標記
if self.do_dino:
dino_loss = self.dino_loss(student_global_cls, teacher_cls_tokens) # 全局裁剪損失
if local_crops is not None:
dino_loss += self.dino_loss(student_local_cls, teacher_cls_tokens) # 局部裁剪損失
loss_dict["dino_loss"] = dino_loss
total_loss += self.dino_loss_weight * dino_loss
# 計算 iBOT 損失:讓學生模型重建被遮罩的 patch 標記
if self.do_ibot:
ibot_loss = self.ibot_patch_loss(student_patch_tokens, teacher_patch_tokens, masks)
loss_dict["ibot_loss"] = ibot_loss
total_loss += self.ibot_loss_weight * ibot_loss
# 反向傳播:根據總損失更新學生模型參數
self.backprop_loss(total_loss)
return loss_dict
SD-DINO
”一個畫龍點睛,一個精雕細琢 “ A Tale of Two Features: Stable Diffusion Complements DINO for Zero-Shot Semantic Correspondence
stable-diffusion(穩定擴散模型/SD)
SD通過在潛在空間(latent space)中進行擴散過程,能高效生成高質量圖像。與傳統擴散模型直接操作像素空間不同,Stable Diffusion 先將圖像壓縮到低維潛在表示,然後在潛在空間中進行去噪,從而降低計算成本並保持生成質量。
- 擴散過程:
- 訓練階段:模型從真實圖像開始,逐步添加高斯噪聲,生成一系列越來越噪聲的版本(前向過程)。
- 生成階段:模型從純噪聲開始,通過學習到的去噪網絡(通常是 U-Net 架構)逐步還原圖像(反向過程)。
- 潛在空間:
- 使用預訓練的自動編碼器(Autoencoder)將圖像壓縮到潛在空間,減少計算量。
- 去噪過程在潛在空間進行,最後解碼回像素空間,生成高解析度圖像。
- 條件生成:
- Stable Diffusion 支援條件輸入(如文字描述、圖像提示),通過交叉注意力(Cross-Attention)機制將文字或圖像信息融入生成過程,實現“文生圖”或“圖生圖”。
文本-圖像的生成模型(下文代指SD)有效地将文本提示与图像中的内容联系起来,因此它们应该能够理解图像中包含的内容。並且可以生成特定场景并对对象的布局和位置有一定程度的控制 ,所以它们应该能够定位对象並能夠實現語義分割

語義分割,不同顏色代表不同部分
SD-DINO 將SD特徵和DINO特徵簡單組合,通过语义对应关系(一项经典的视觉任务,旨在连接两幅或多幅图像中的相似像素)来研究稳定扩散 (SD) 特征。得到結論:SD 特征与现有的表示学习特征(例如最近发布的 DINOv2)相比具有非常不同的特性:DINOv2 提供稀疏但准确的匹配,而 SD 特征提供高质量的空间信息,但有时==语义匹配==不准确。
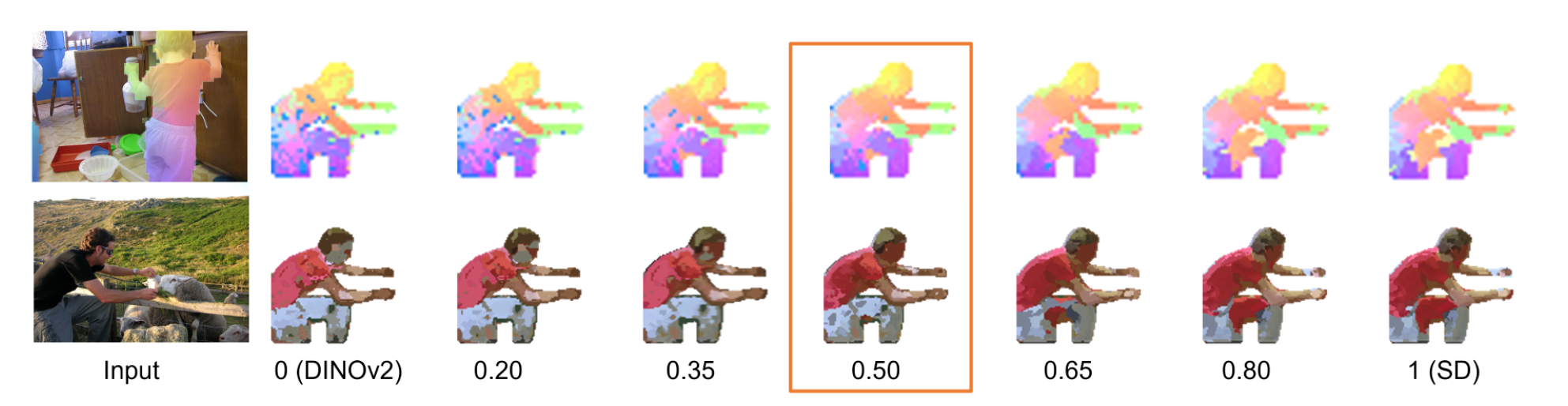
DINO和SD特徵的權重圖,最左側的身體部位連續且噪點很少,但是位置不對(==高質量的空間信息==)。最有側雖然位置精確但是噪點很多不連續(==稀疏但準確的匹配==)。
特徵檢測和特徵匹配
稠密
计算一幅图像的一个小窗口函数,窗口内的像素与另一幅图像中具有同样的潜在对应特征的大小窗函数的像素之间的相关值,具有最大相关性的小窗口区域就是对应区域
簡單說就是像素與像素之間的對應

稀疏
基于特征(点、线)的匹配称作稀疏匹配。
在立体图像对中识别兴趣点而后在两幅图像中匹配相对应的点。
簡單說就是基於較大部分(部位)的匹配,不再關注具體的像素值

代碼部分(精簡)
def compute_pair_feature(model, files, category, dist='cos', img_size=840):
"""
為一對圖像提取 DINOv2 和 Stable Diffusion 特徵,用於語義對應任務。
返回特徵描述,支援 SD(全局語義)和 DINOv2(局部精確)的融合。
"""
device = 'cuda' if torch.cuda.is_available() else 'cpu'
extractor = ViTExtractor('dinov2_vitb14', stride=14, device=device) # 初始化 DINOv2 模型
result = []
for pair_idx in range(len(files) // 2):
# 載入並預處理圖像對
img1 = Image.open(files[2 * pair_idx]).convert('RGB')
img2 = Image.open(files[2 * pair_idx + 1]).convert('RGB')
img1 = resize(img1, img_size, resize=True, to_pil=True)
img2 = resize(img2, img_size, resize=True, to_pil=True)
with torch.no_grad():
# 提取 Stable Diffusion 特徵(全局語義)
img1_sd = process_features(model, img1, category=category[-1])
img2_sd = process_features(model, img2, category=category[-1])
# 提取 DINOv2 特徵(局部結構)
img1_batch = extractor.preprocess_pil(img1)
img1_dino = extractor.extract_descriptors(img1_batch.to(device), layer=11, facet='token')
img2_batch = extractor.preprocess_pil(img2)
img2_dino = extractor.extract_descriptors(img2_batch.to(device), layer=11, facet='token')
# 融合 SD 和 DINOv2 特徵,增強語義對應
img1_desc = torch.cat((img1_sd, img1_dino), dim=-1)
img2_desc = torch.cat((img2_sd, img2_dino), dim=-1)
# 正規化特徵,準備相似性計算
if dist in ['l1', 'l2']:
img1_desc = img1_desc / img1_desc.norm(dim=-1, keepdim=True)
img2_desc = img2_desc / img2_desc.norm(dim=-1, keepdim=True)
# 儲存特徵描述,供語義對應使用
result.append([img1_desc.cpu(), img2_desc.cpu()])
return result

飞机的特征匹配,效果一般
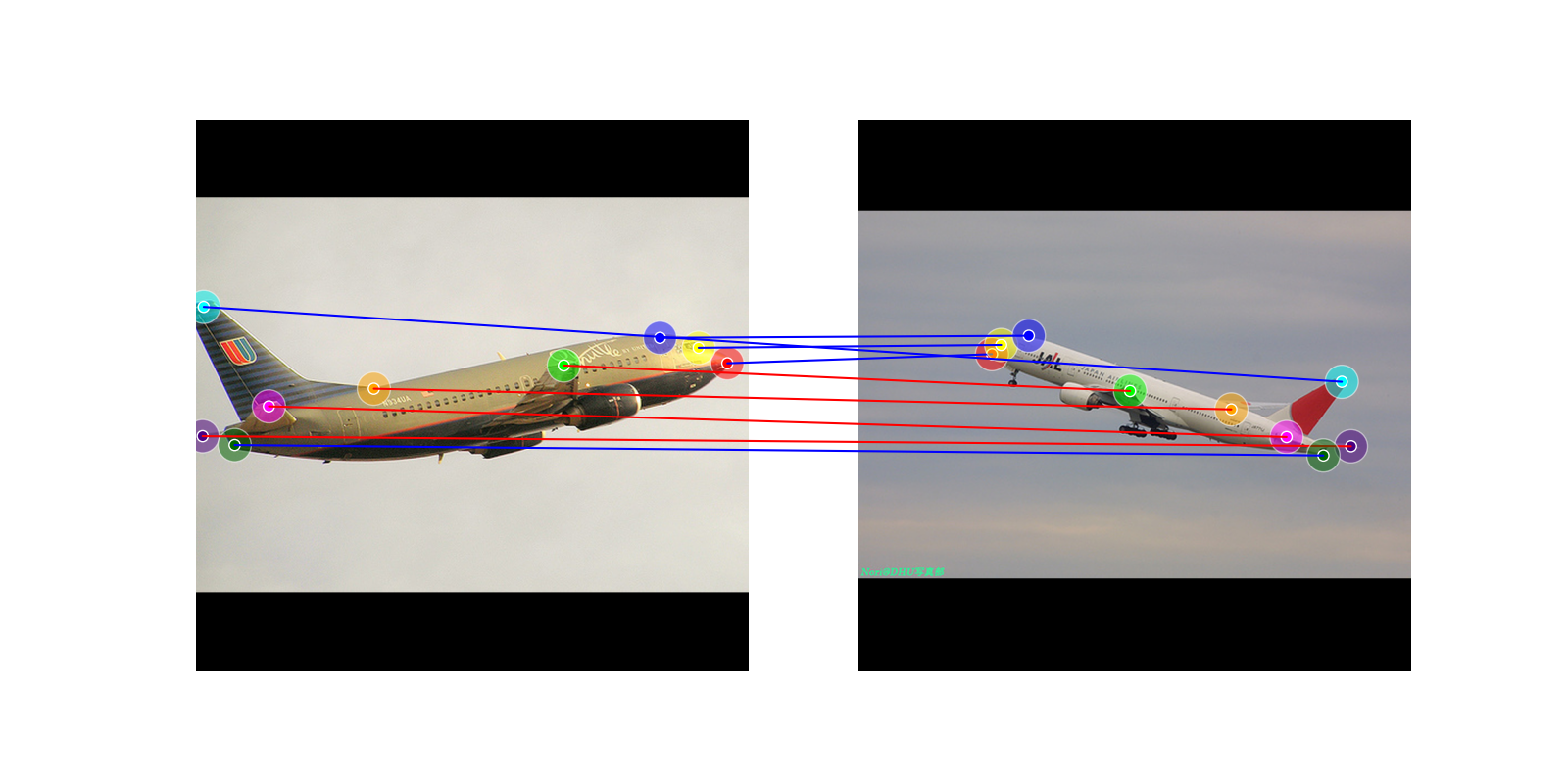
飞机的稀疏匹配
2 -
``#### 回歸和分類

數據集:圖片,視頻,表格



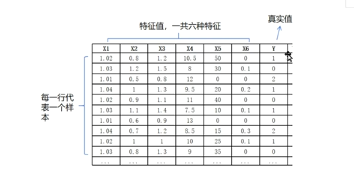
特徵值可以理解爲屬性




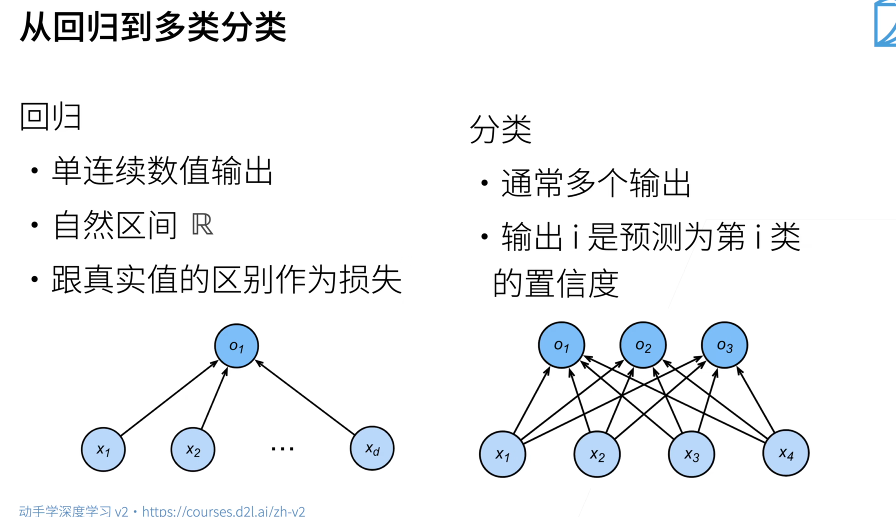
從回歸到分類
對於分類來說,不太關心實際的數值如何,而是使正確類別的置信度最大即可 也就是讓某一類 Oy遠大於其他類
極大似然估計
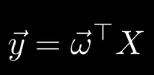
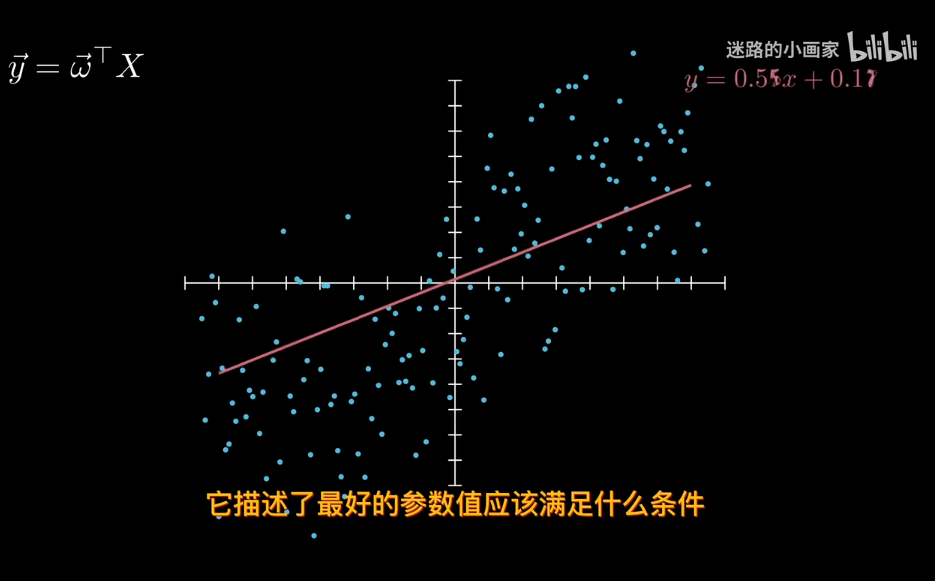
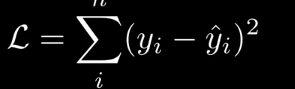
在正態分佈中
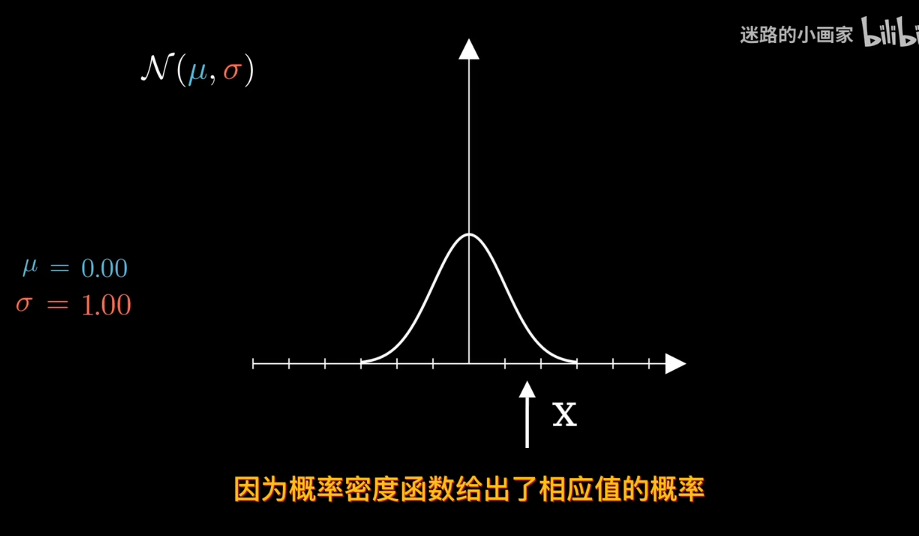
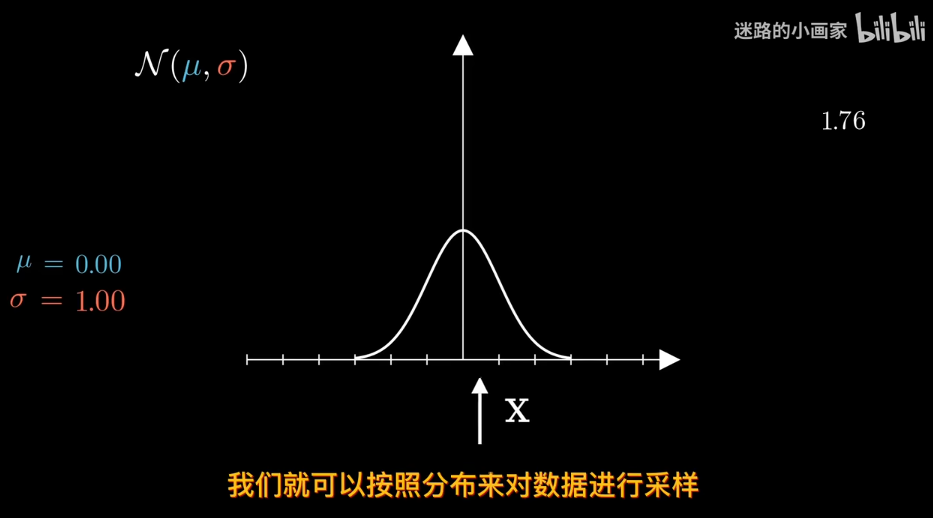
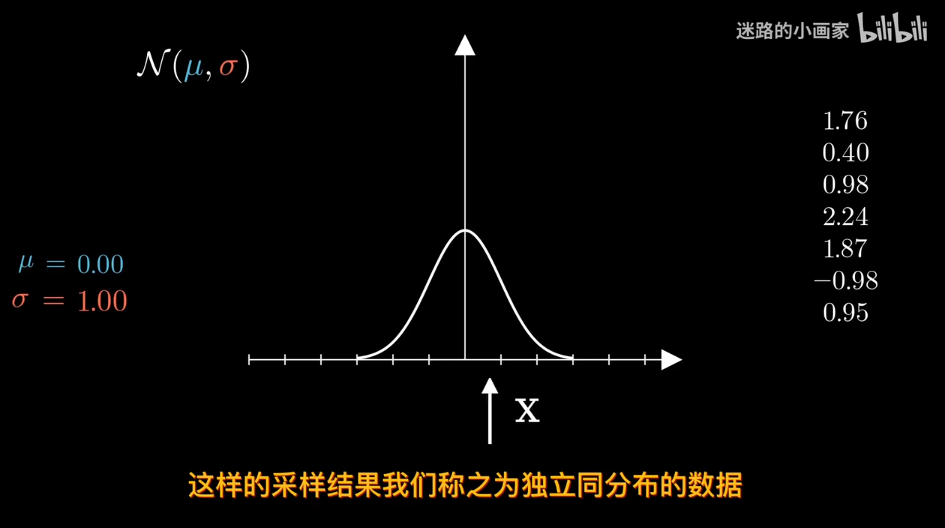
給定數據確定分佈?
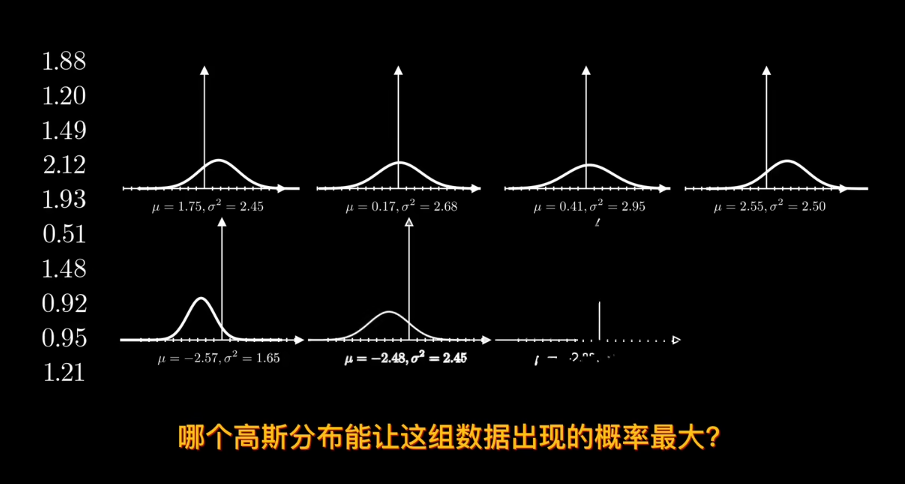


知道概率分佈求概率叫估計 知道概率求分佈叫似然
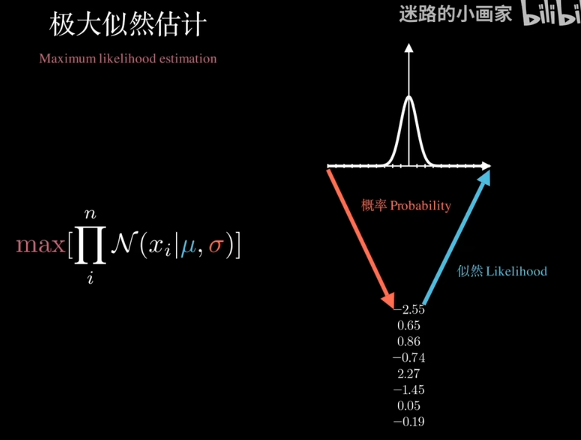
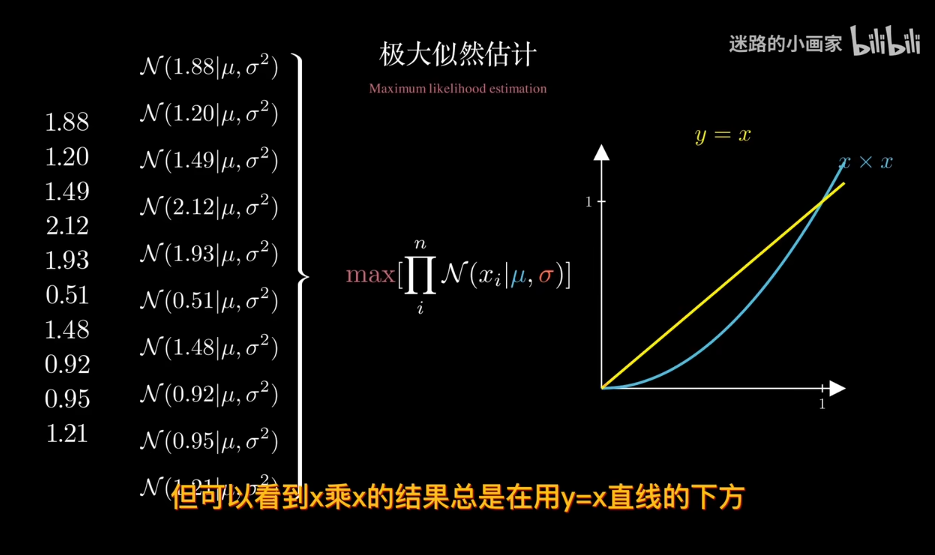
結果會非常小,甚至爲0


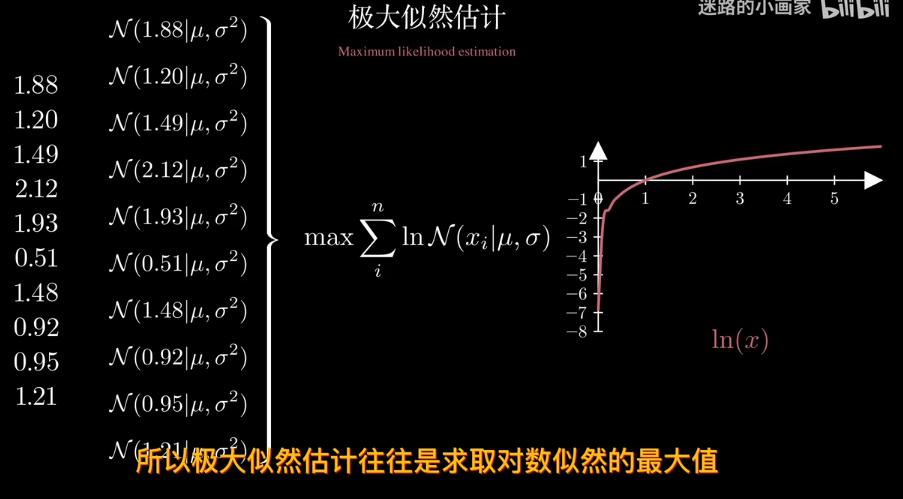
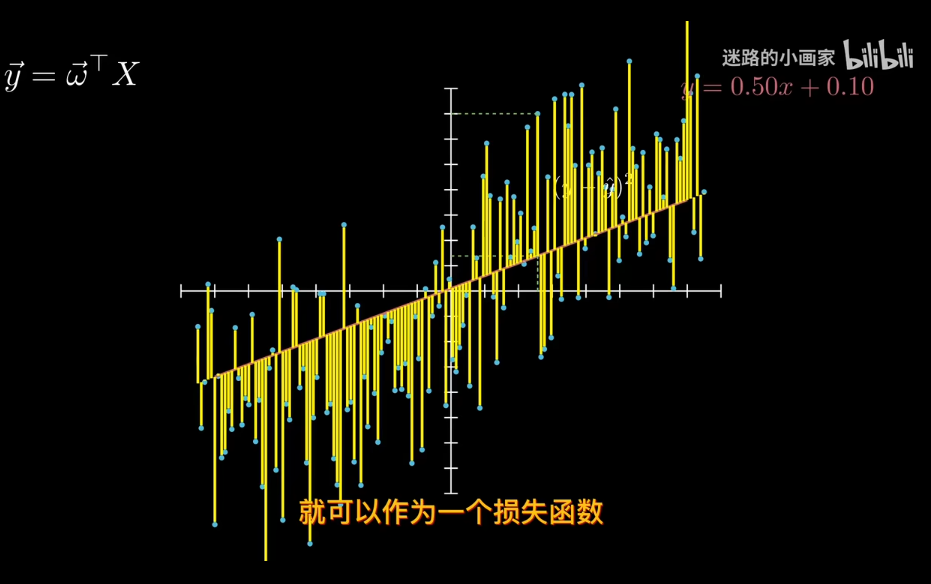
回到線性回歸

x已知下,y是不確定的.

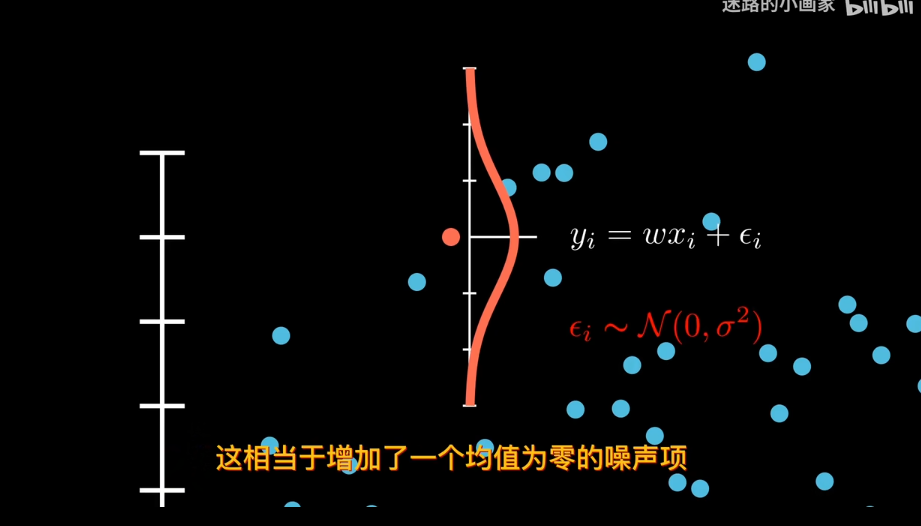
均值為 0 的假設還意味著噪聲是「無偏」的,即它不會系統性地高估或低估目標值,而是在 f(x)附近隨機波動。

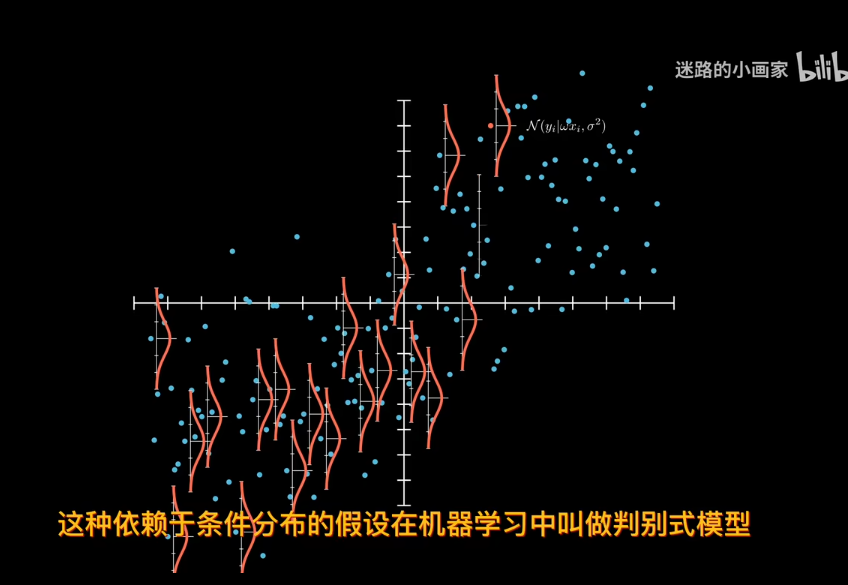
對分佈化簡,剔除與模型無關的噪聲sigma
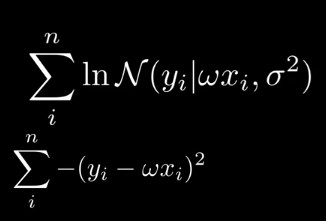
現在求w的最可能值。對於同分佈數據點,求極大似然估計。
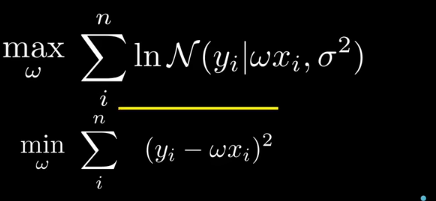 ‘
‘

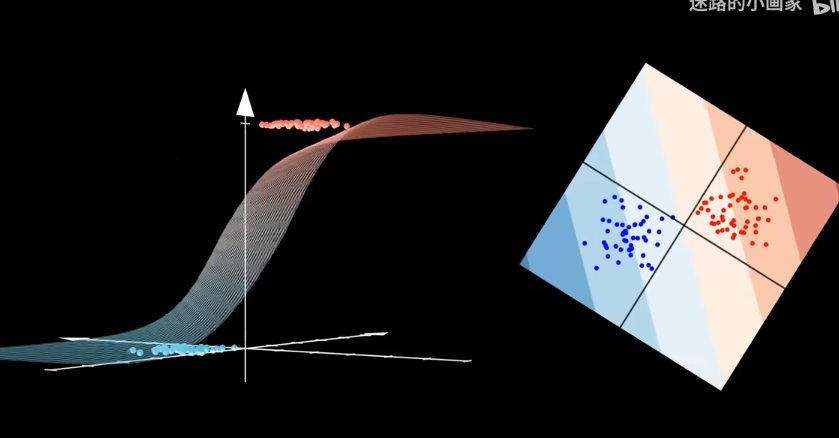
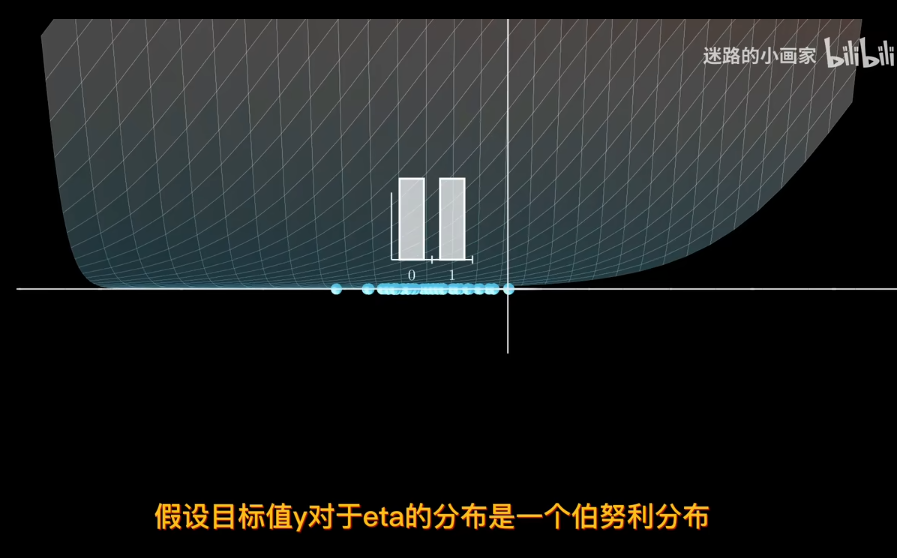
線性回歸中,目標值y假設是由高斯分佈採樣而來,也就是說值域爲實數
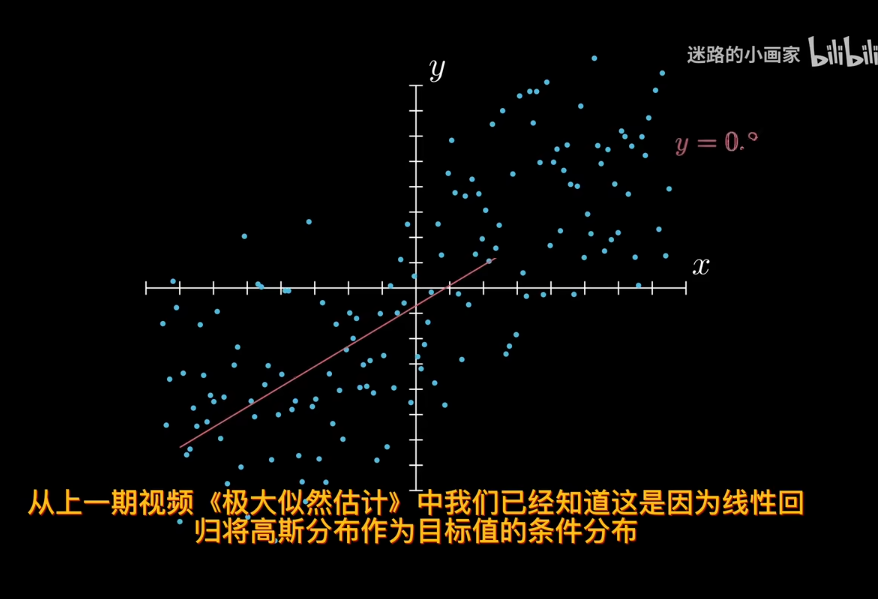
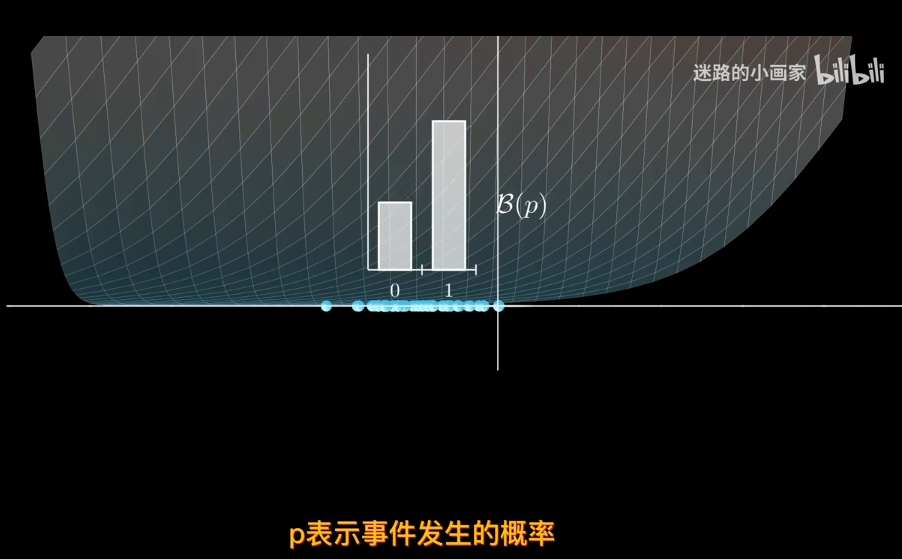
但二分類問題,目標值只能取0或者1,也就是值域的範圍發生了變化
那麼引入參數來表是線性模型輸出結果
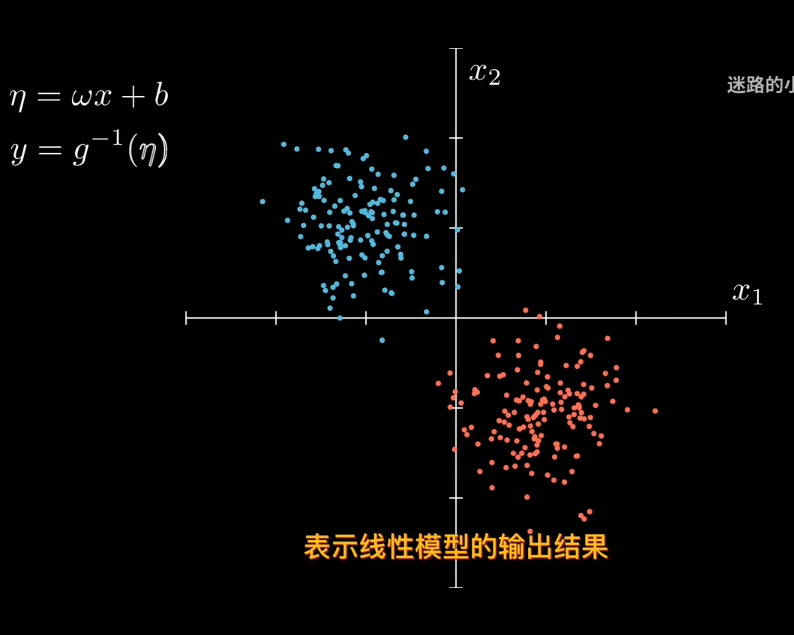
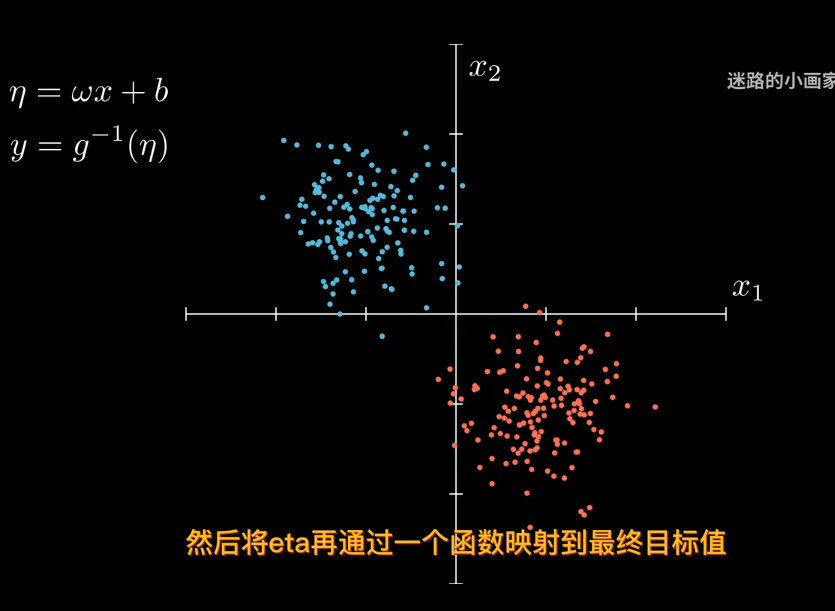
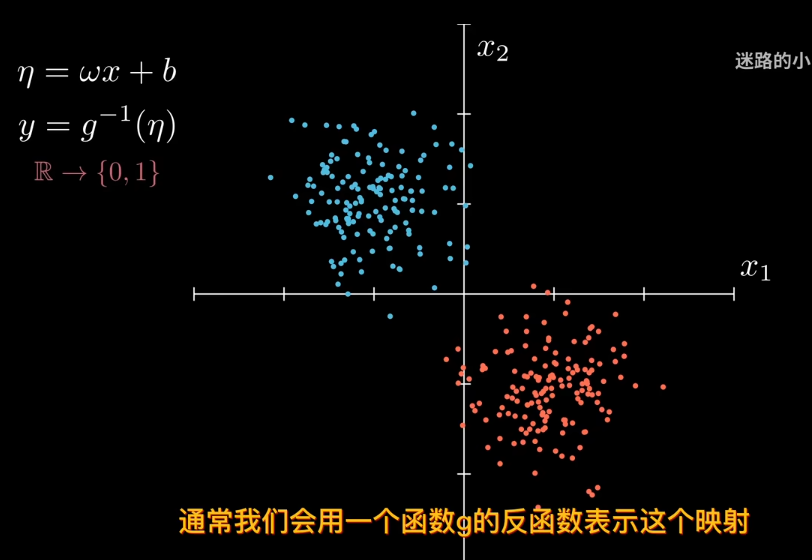
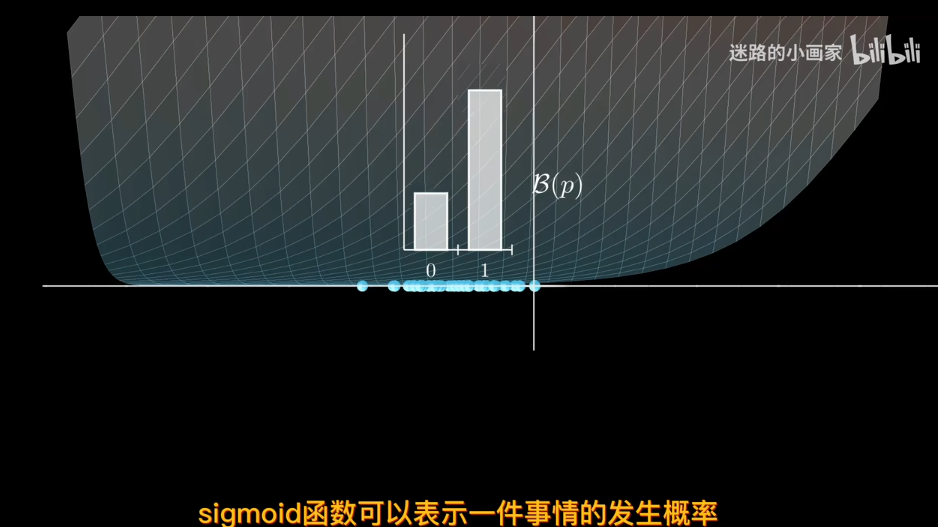
比如sigmod函數
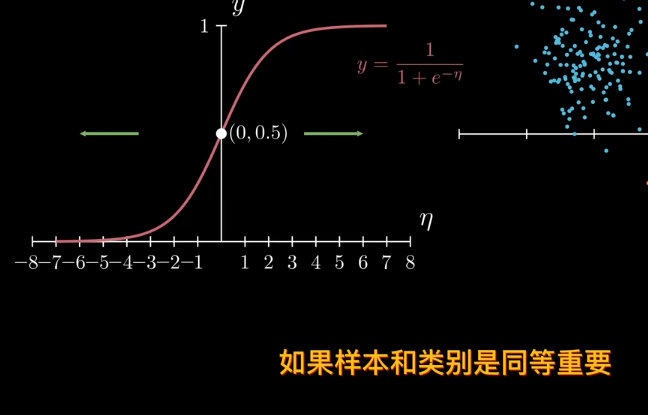
但sigmod函數是中心對稱,也就是說樣本和類別同等重要,不存在某一種類別對目標值的貢獻低
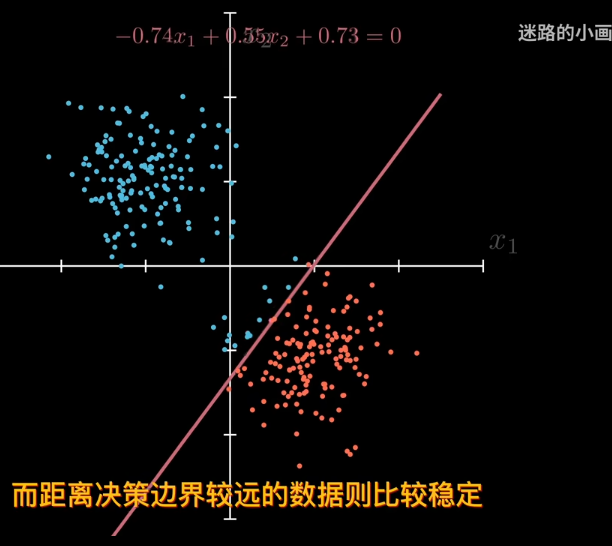
因爲sigmod單調,可以賦予概率。離決策邊界越遠屬於該類概率越大
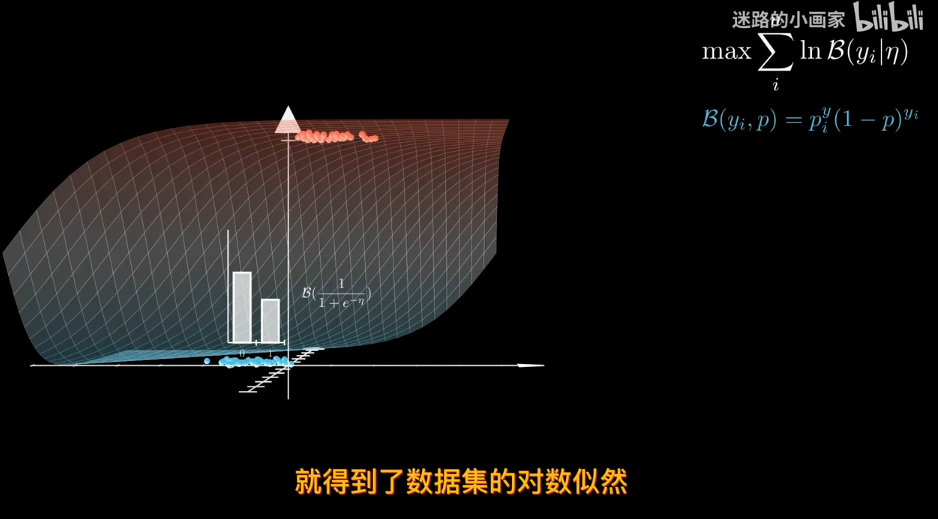
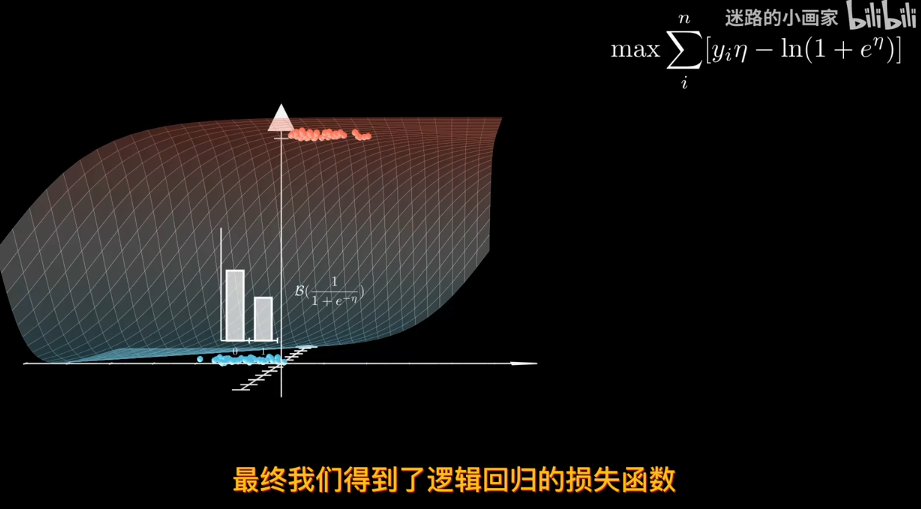
那麼爲了找出最合適的決策邊界,需要定義一個損失函數 比如利用極大似然估計
因此sigmod函數可以作爲參數p 對於同分佈獨立數據集,可以用極大似然估計來找到最合適的邊際
SoftMAX








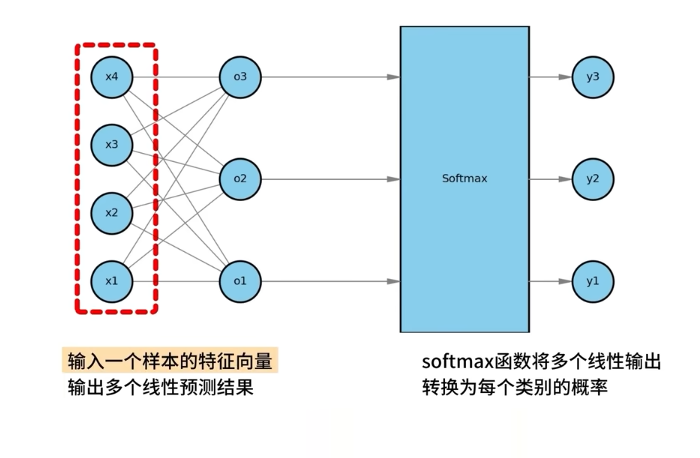
得到O“3*1” 後,輸入o到softmax,得到概率
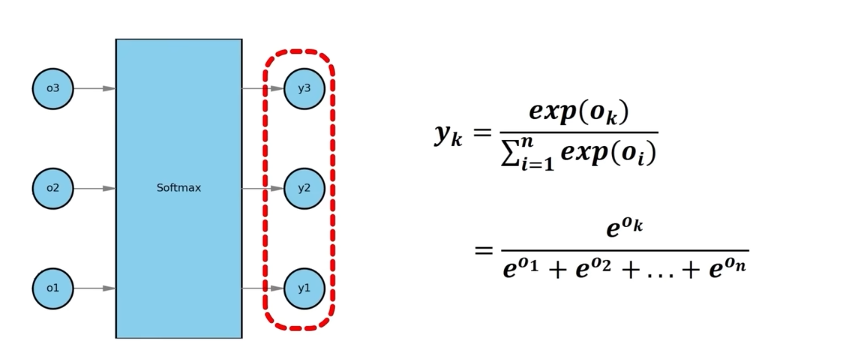
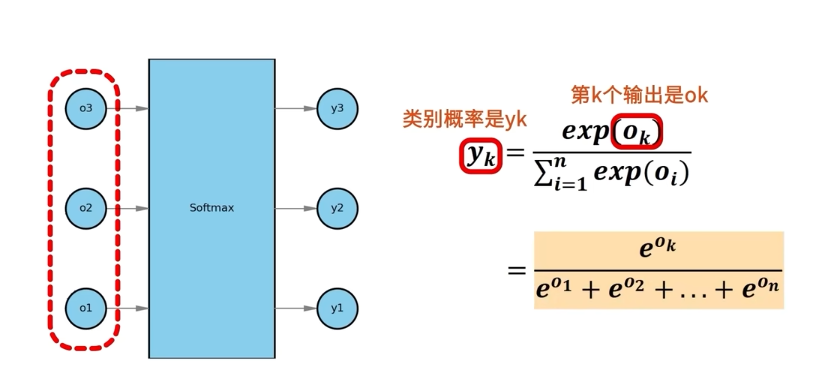
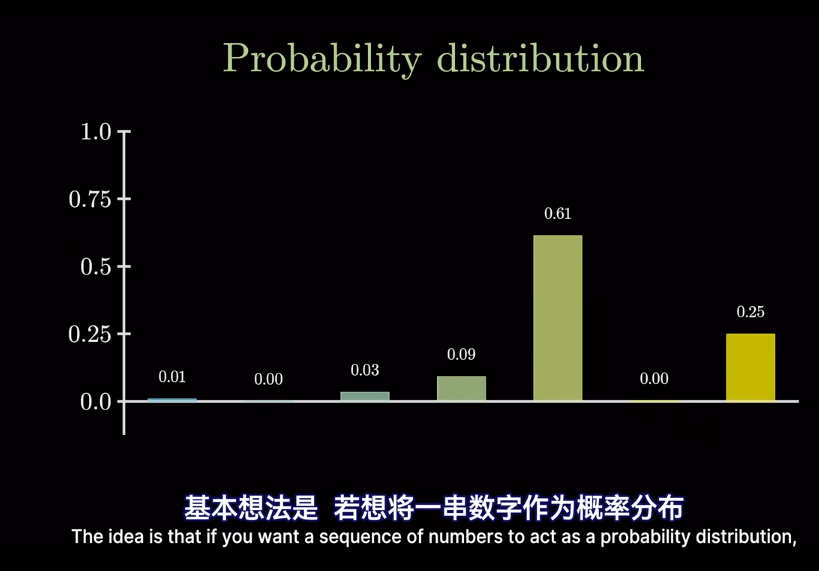
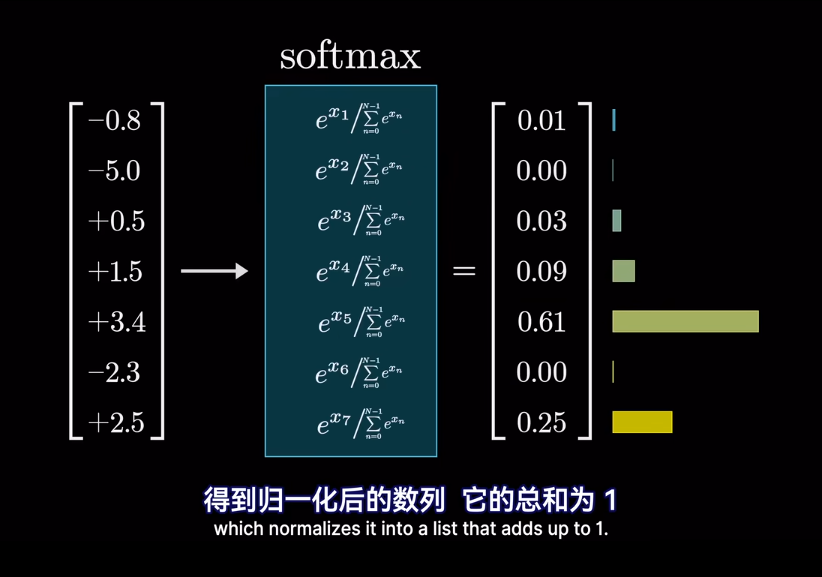 經過softmax後,可以保證概率非負,並且總和爲1,也就是所有類別的概率相加爲1
經過softmax後,可以保證概率非負,並且總和爲1,也就是所有類別的概率相加爲1
”我們不關心得到的節點值,我們只關心正確的類別值最大“





Transformer


TTV
TTS
TTI
本文介紹的Transformer是如下類型
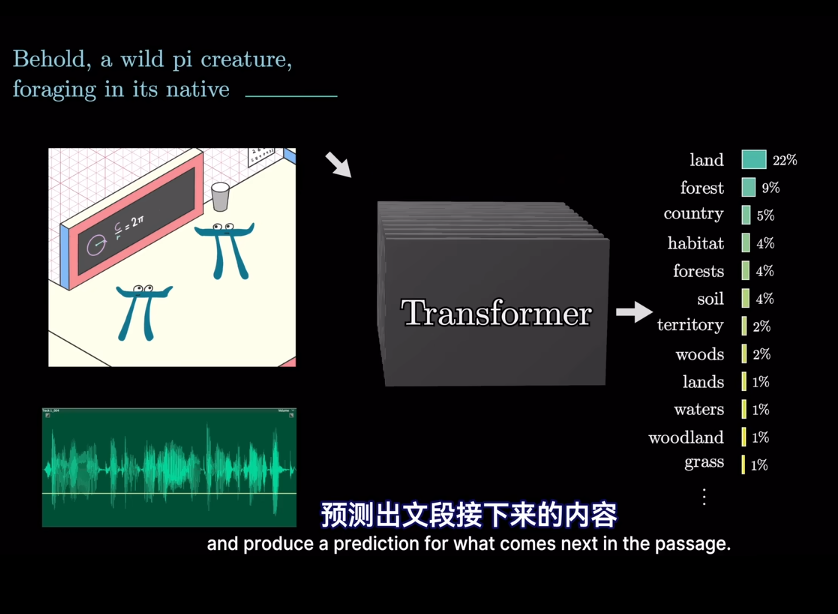




這是爲了編碼該片段的含義
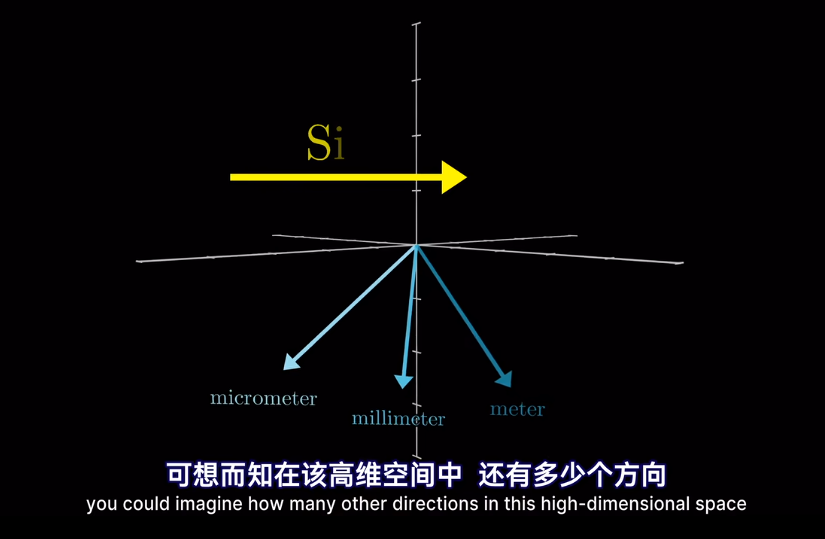
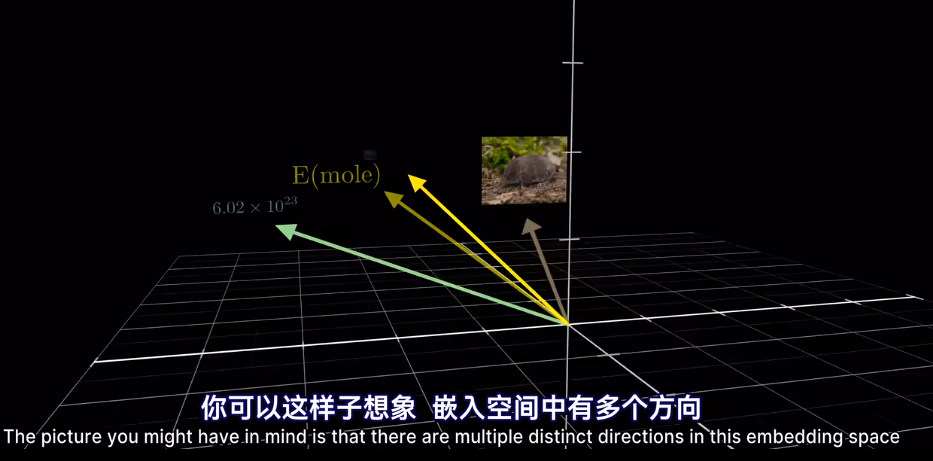
如果將向量看作高維空間座標

在模型的第一層叫做嵌入層



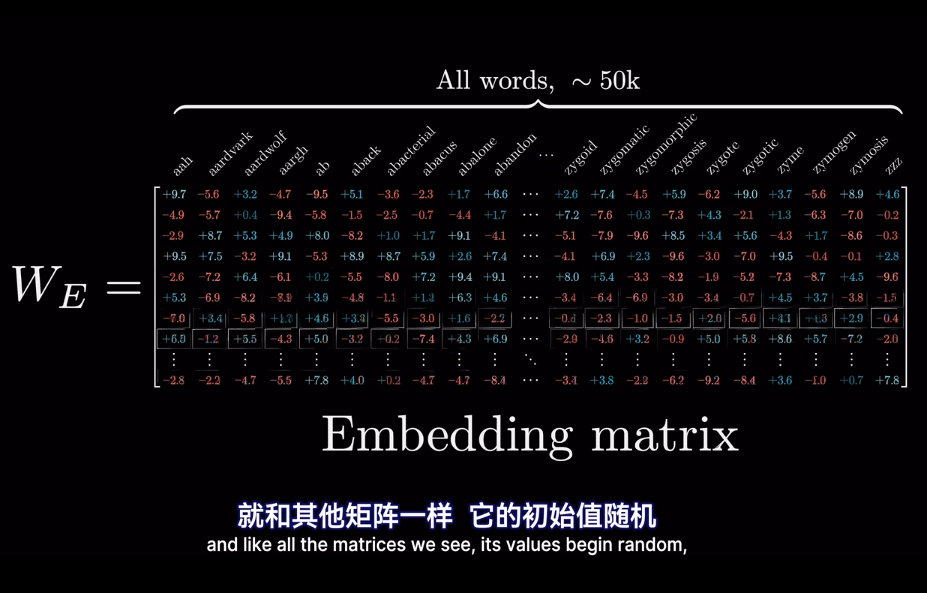

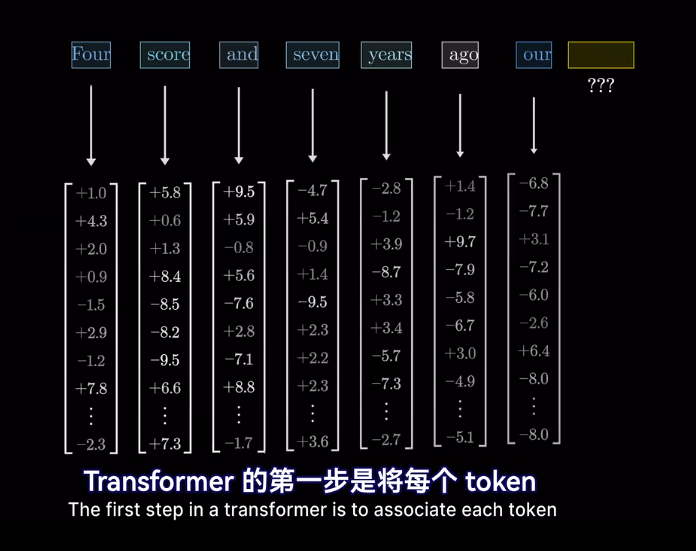

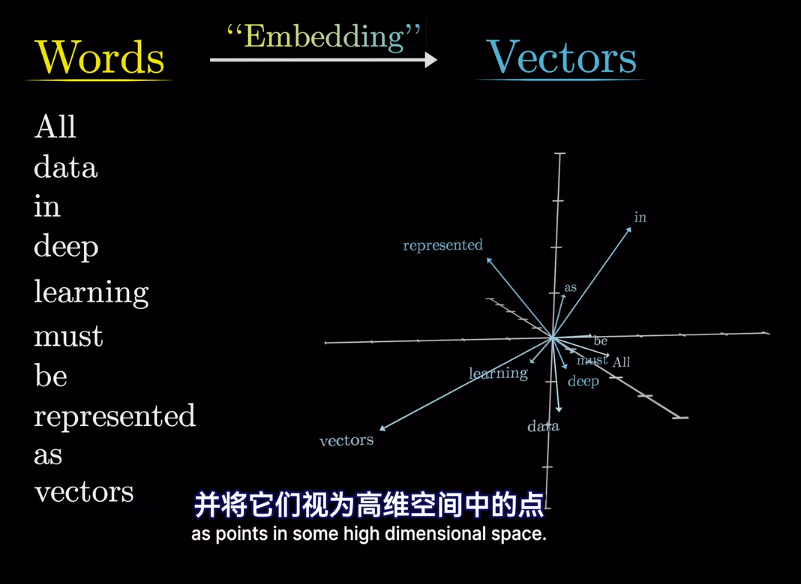
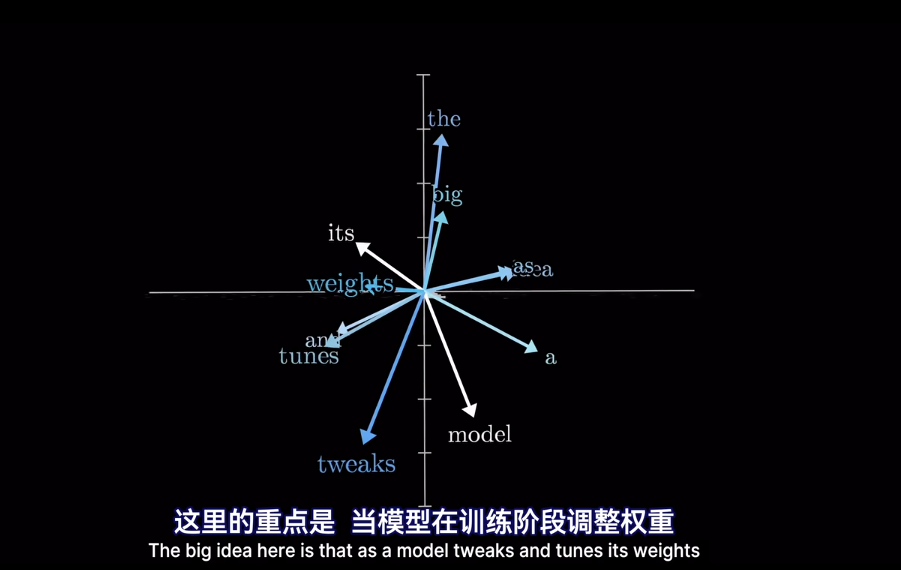
最終的位置會被賦予語義含義

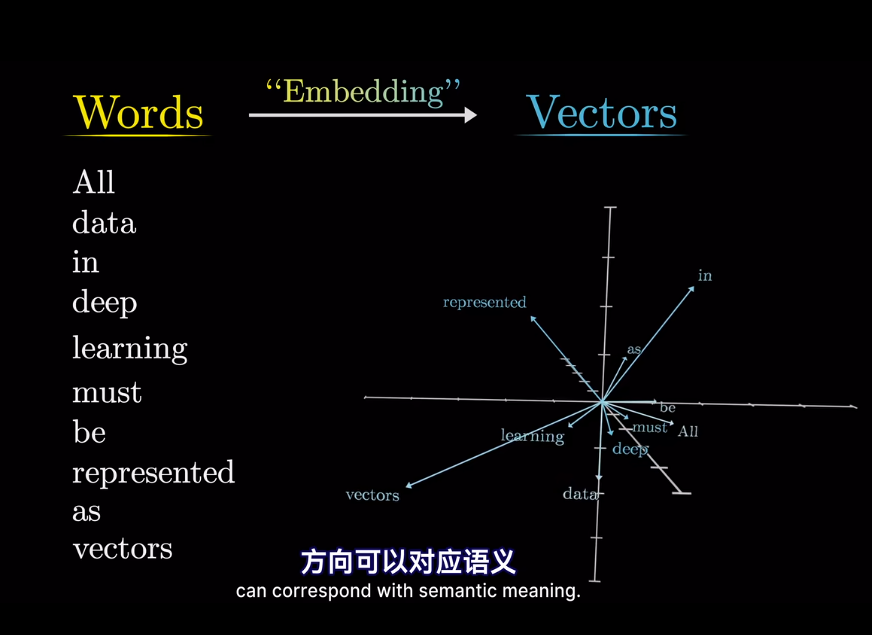
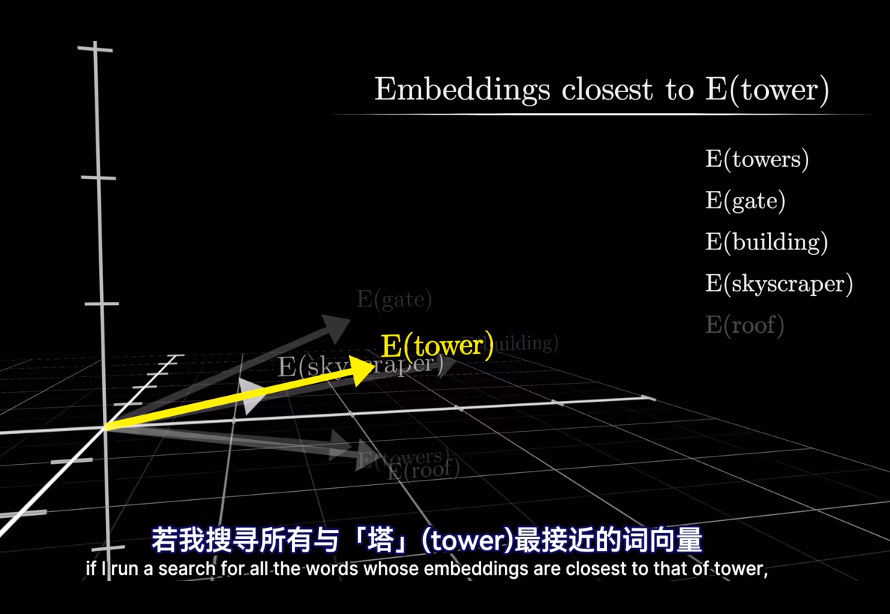

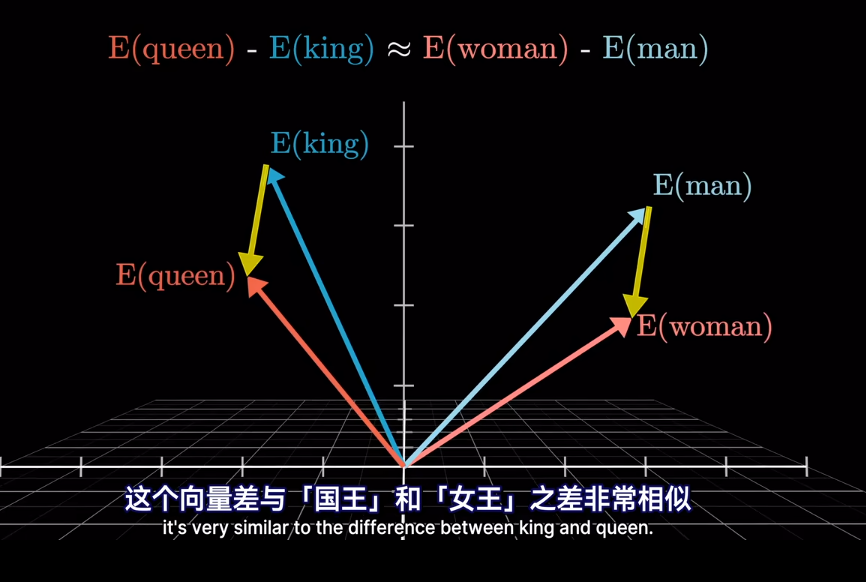

插一句,衡量空間向量接近程度,點乘是個好東西
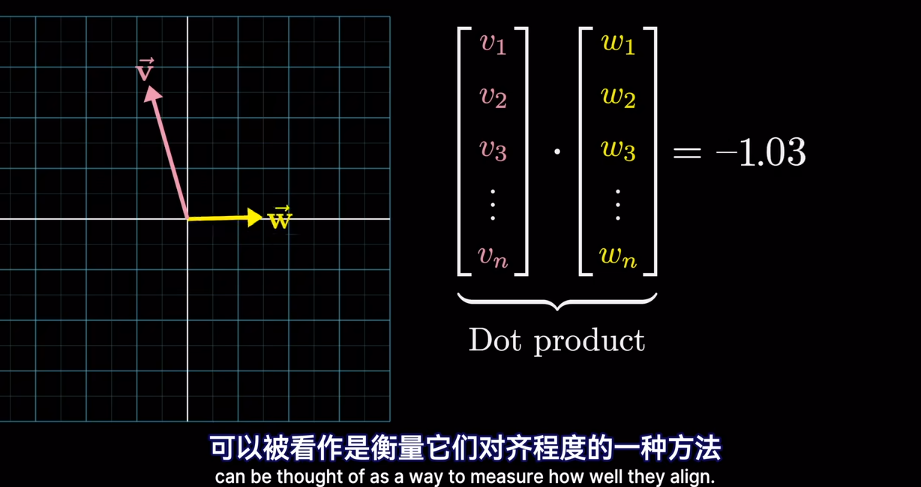

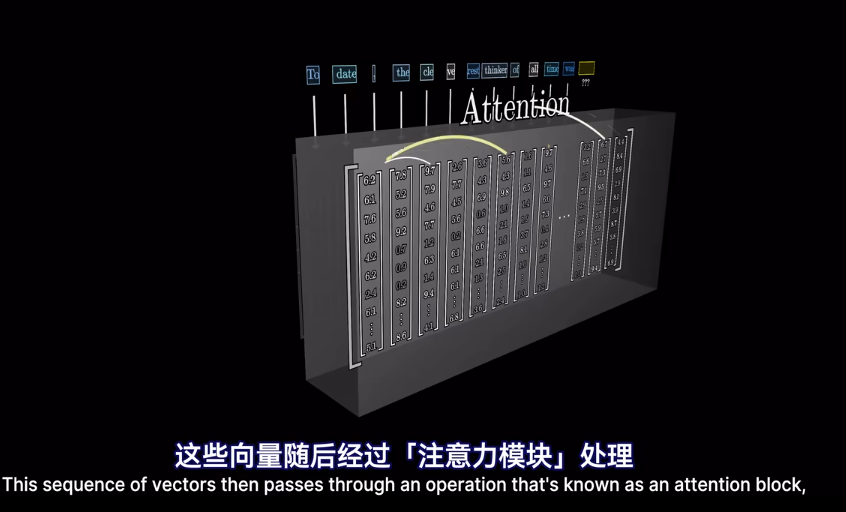


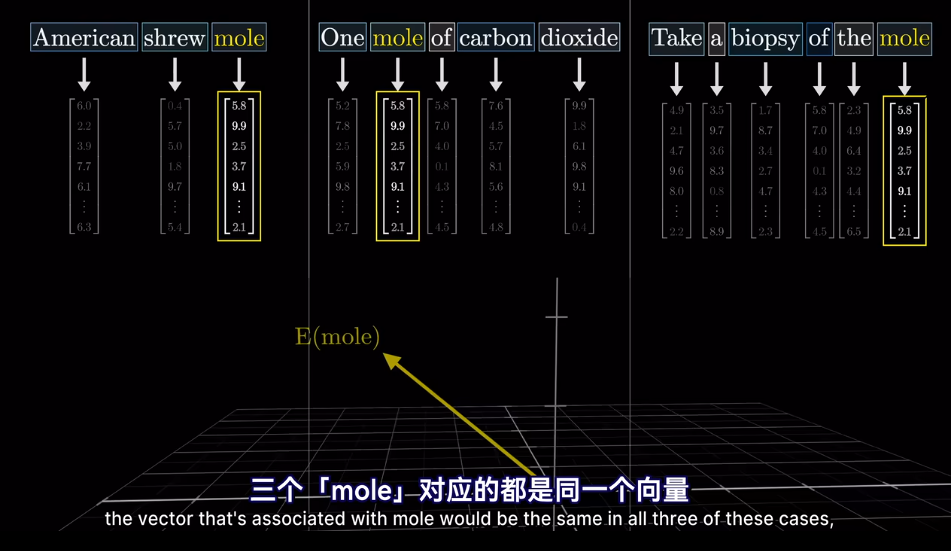
meaning 已經被編碼爲向量,但是在不同的上下文中,語義會改變





這裏需要注意在嵌入矩陣沒有上下文




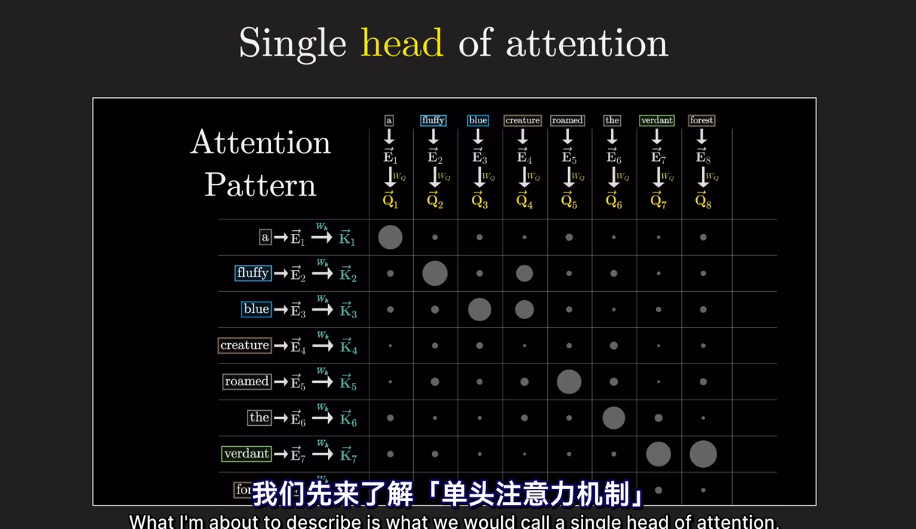
self-attention
在經過attention後





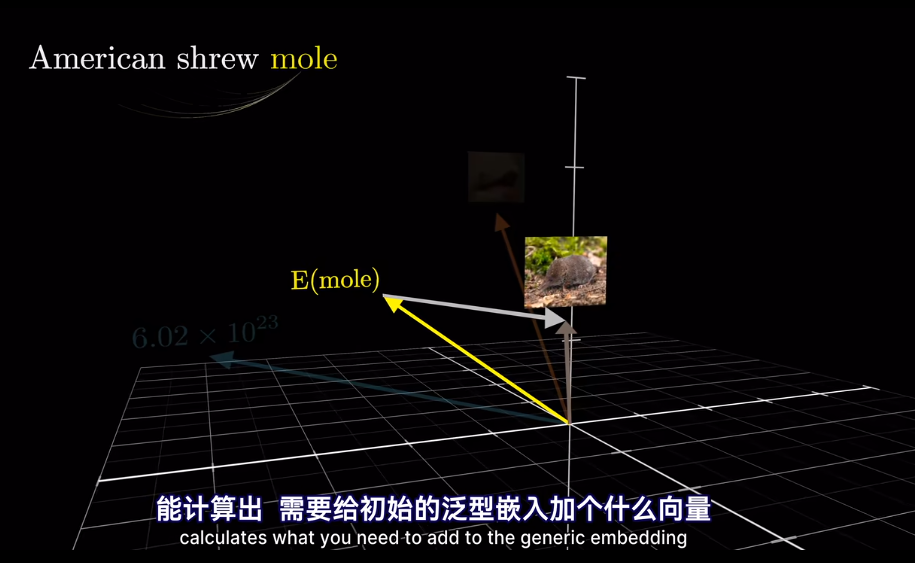

其實在最開始不只是編碼了詞的含義
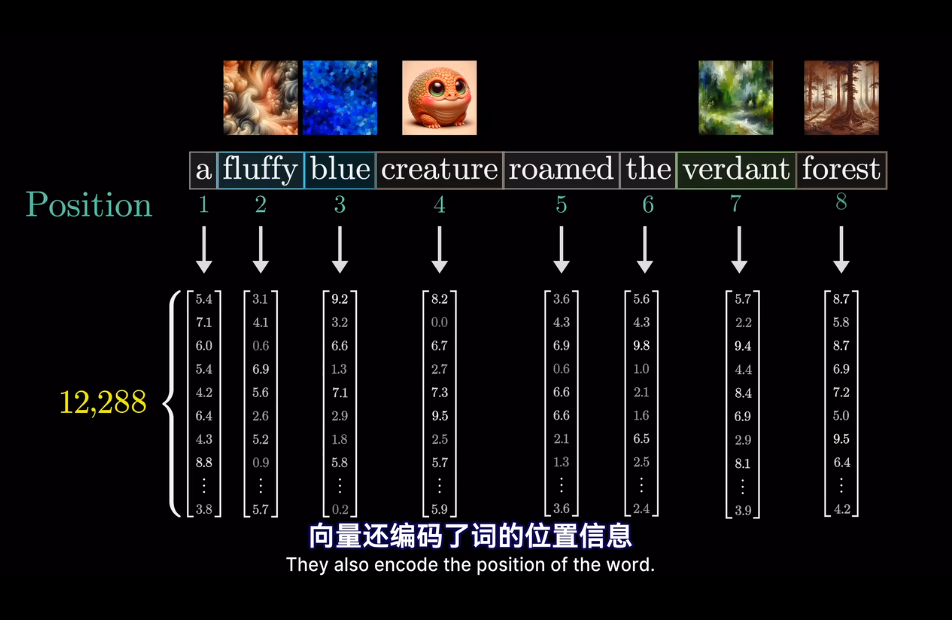

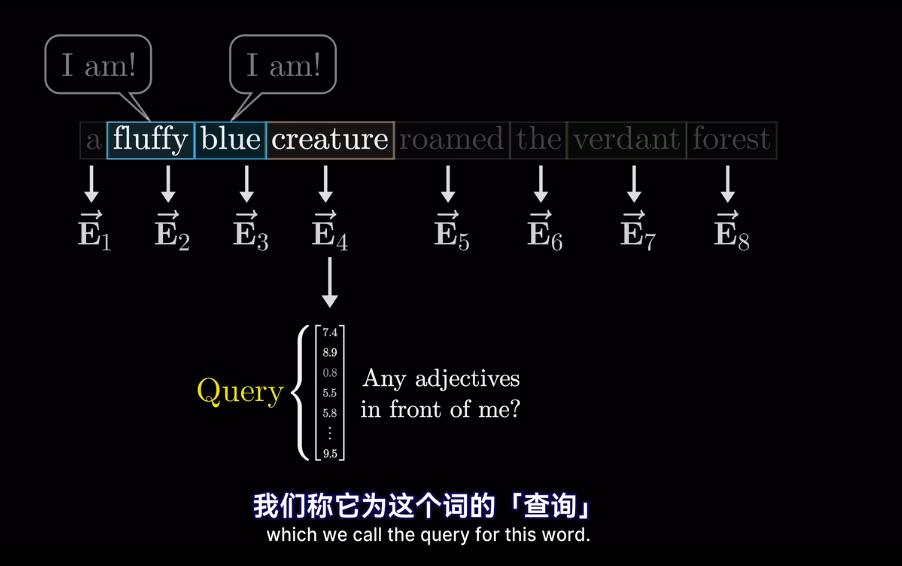
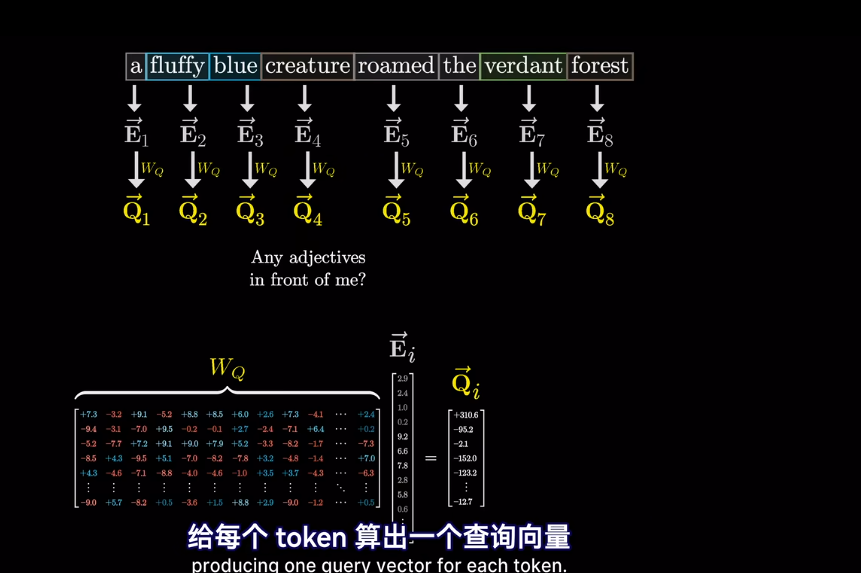
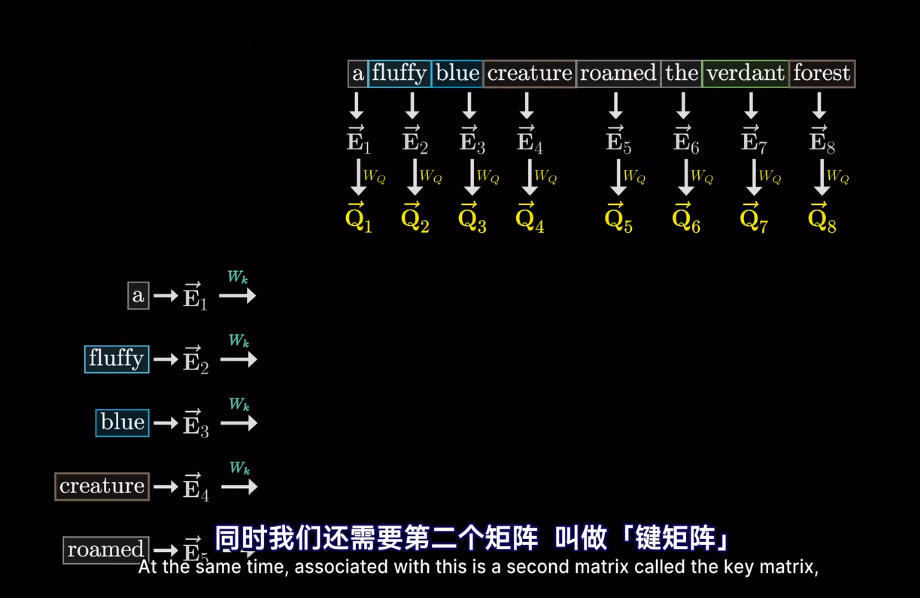
會將高維的詞映射到低維空間
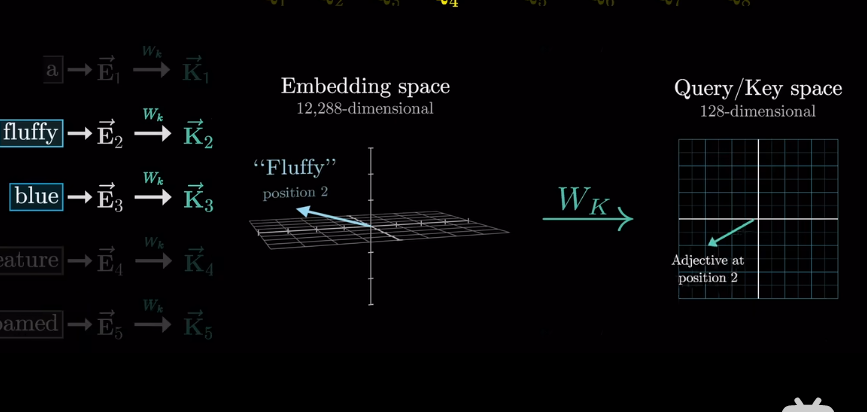
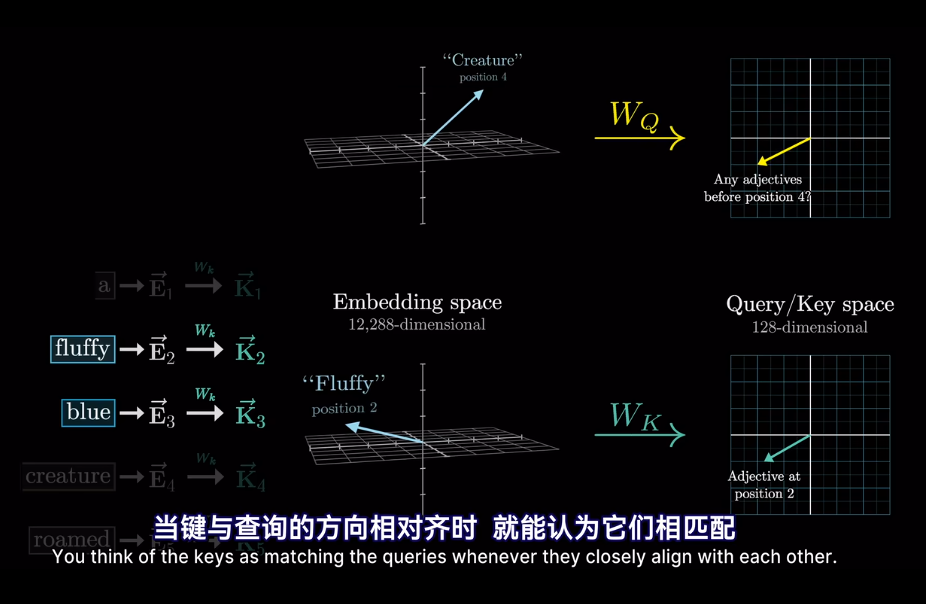
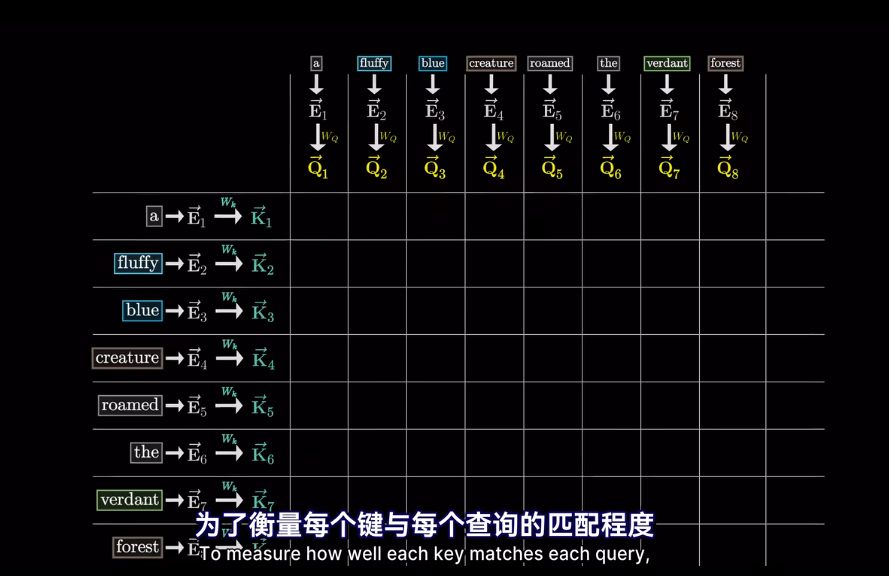
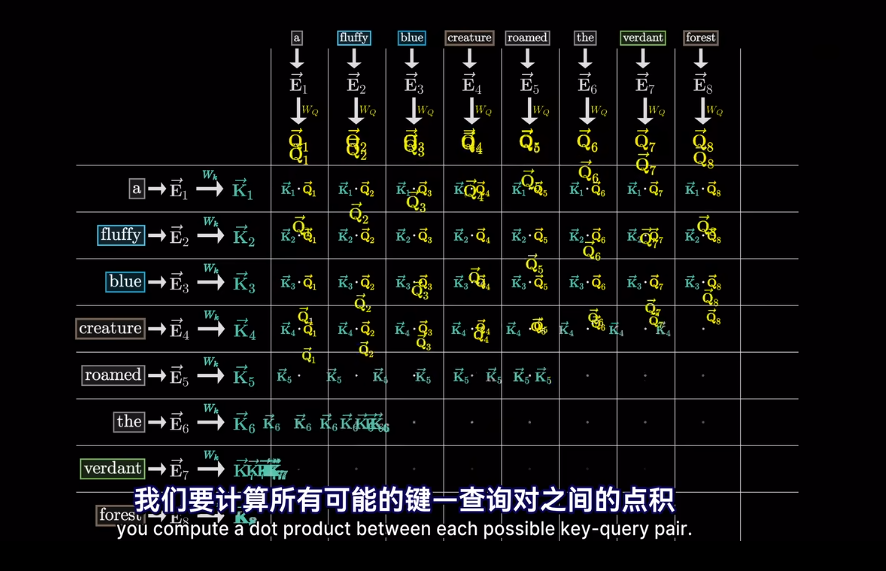


但我們想要的是概率或者說,相關度,也就是最可能關聯的詞。不是單純的數值
softmax

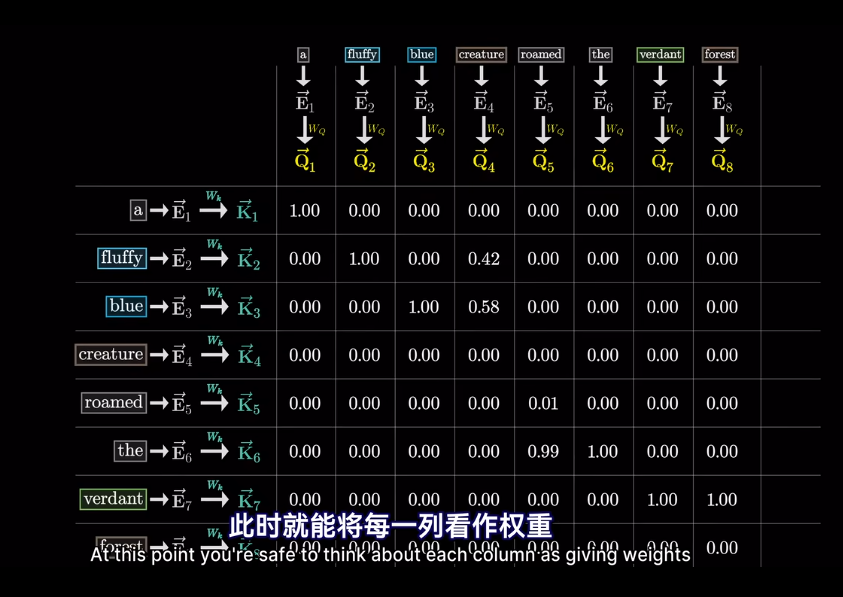

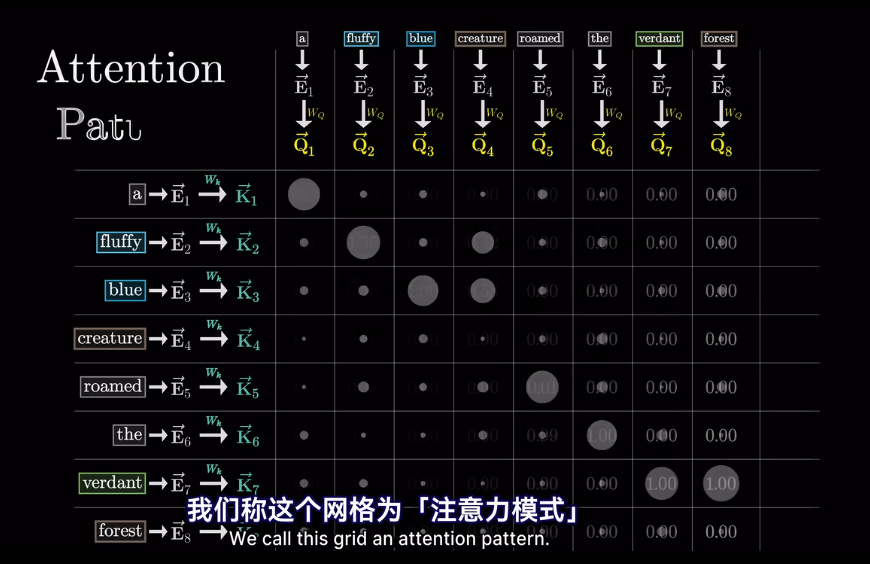
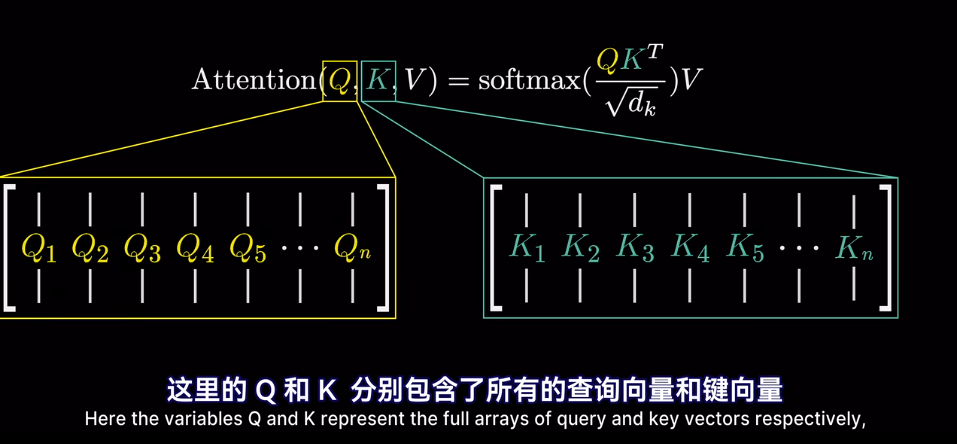


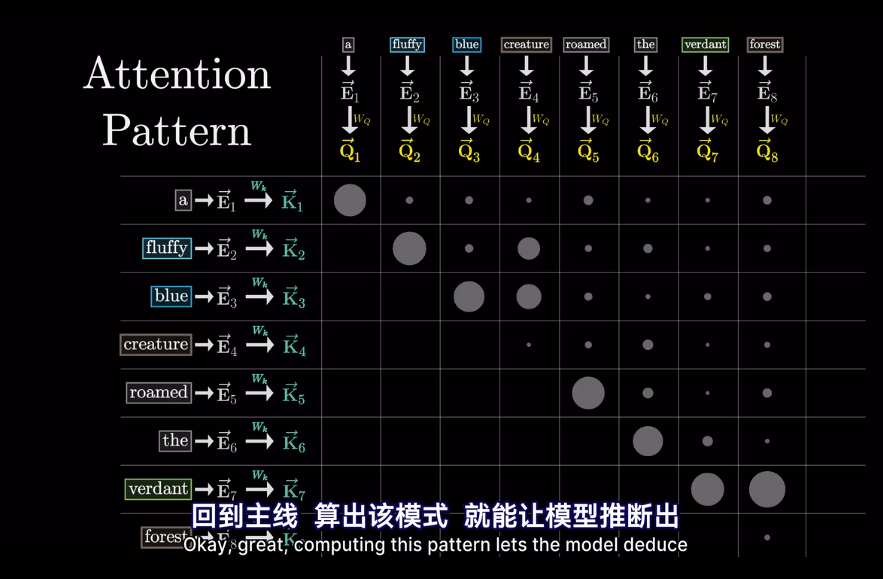

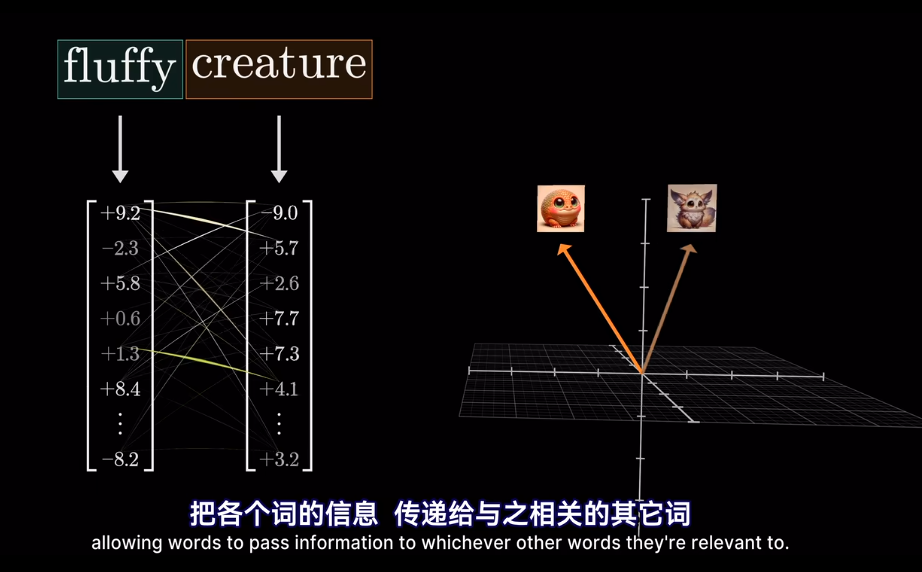


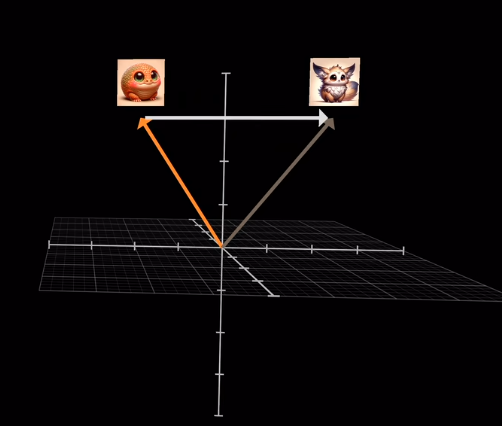
然後求softmax概率,歸一化
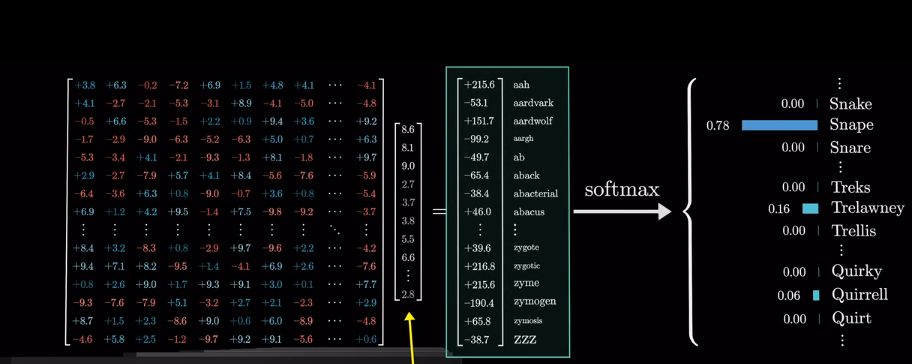

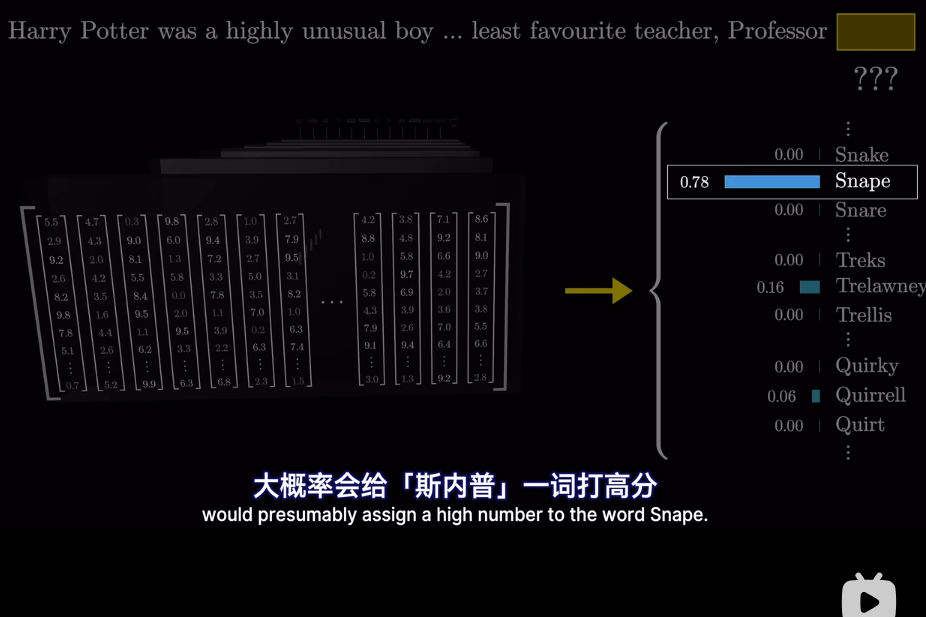
但是爲什麼只用最後一個向量?
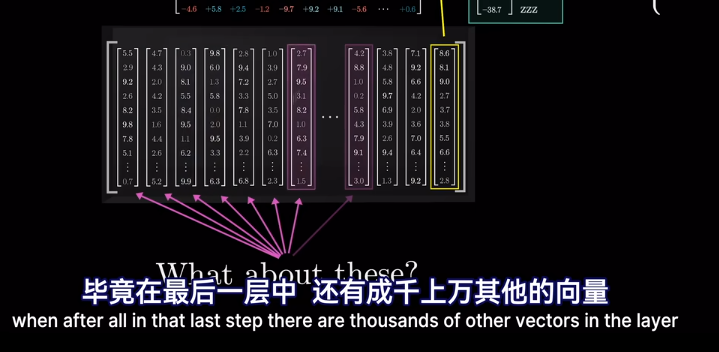

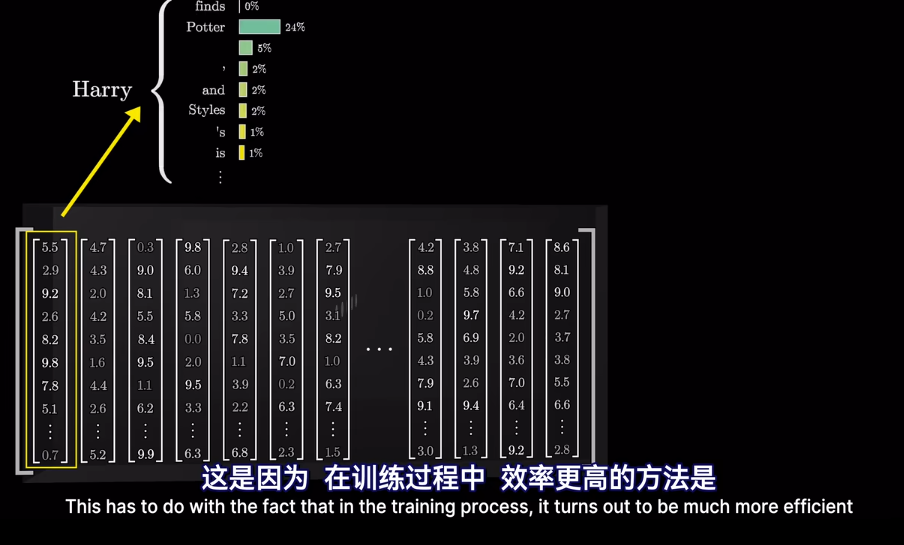


Vsion Transformer
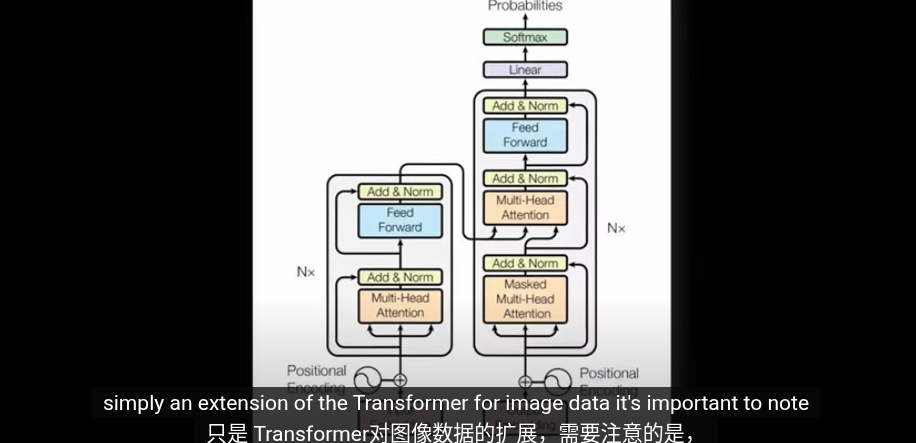
第一步,圖片編碼爲嵌入向量。目的和Transformrer中的嵌入空間類似爲了將相似的圖片放到接近的位置,並給高維空間的圖片賦予含義
但是傳統的Trasformer用於NLP,輸入就是拆分語句形成零碎的單詞以及對應的Token,我們怎麼從圖片裏提取Token?



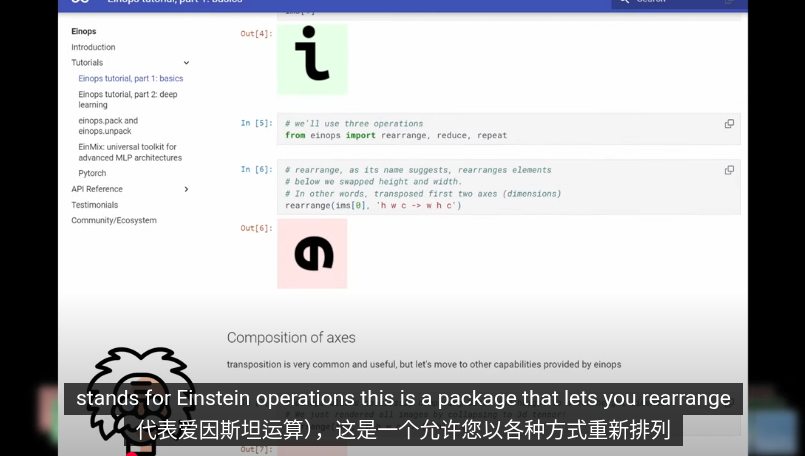
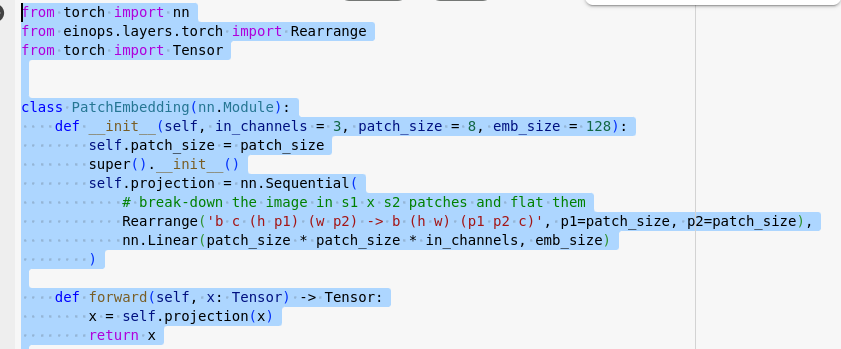
我們使用 inops 來 reshape 也就是切割





有時爲了效率可以用CNN代替
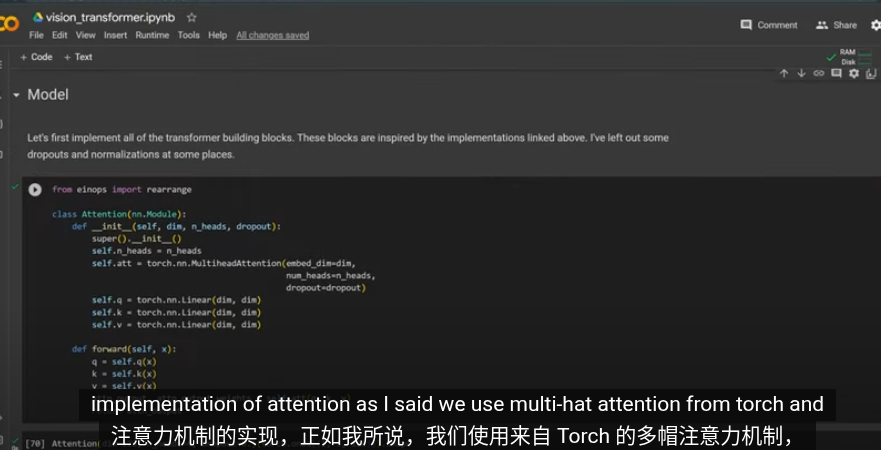
代碼
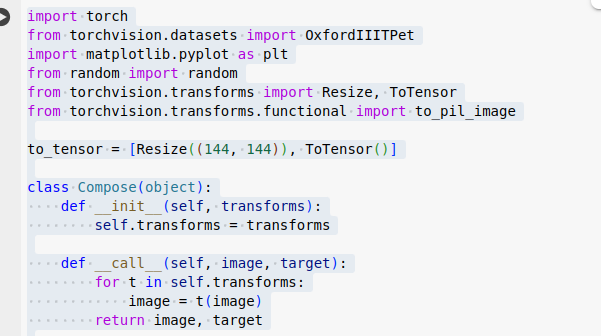
數據集 劍橋動物3 圖片調整爲統一大小,轉爲 tensor

做 inops 操作,展平特徵,輸入線性層裏得到patch embedding 嵌入向量




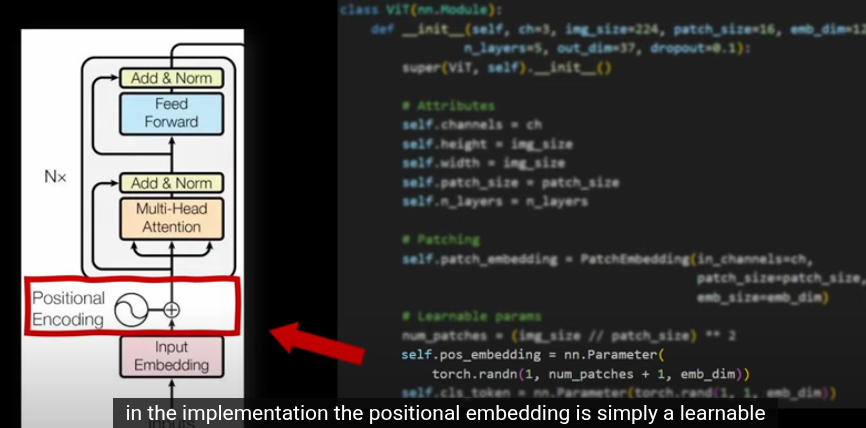
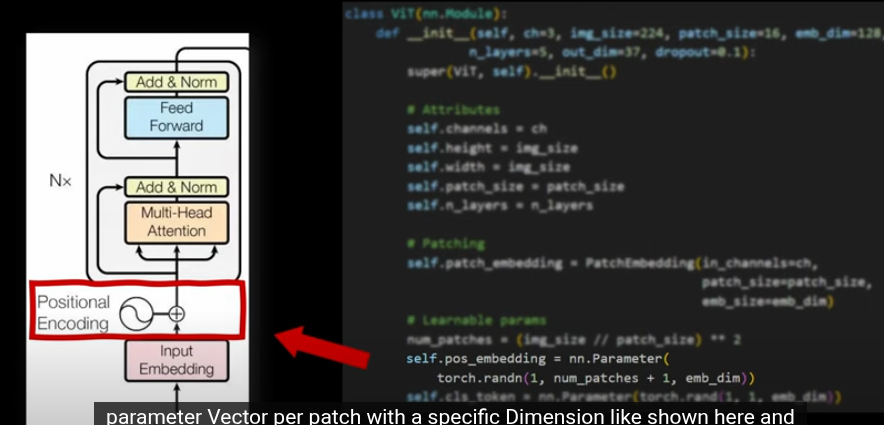
加入位置編碼後,就是經典的transformer了





Knowledge Distillation

關於 model compression 模型壓縮


因爲模型大小的原因,很多模型並未轉化爲實際應用。因爲計算資源,內存是有限的

目前在擴大規模訓練上成果顯著


這存在許多問題
我們把重點放在知識蒸餾




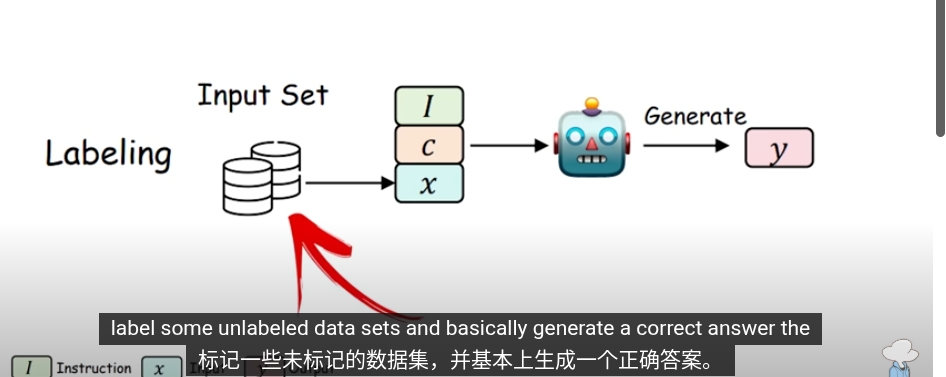
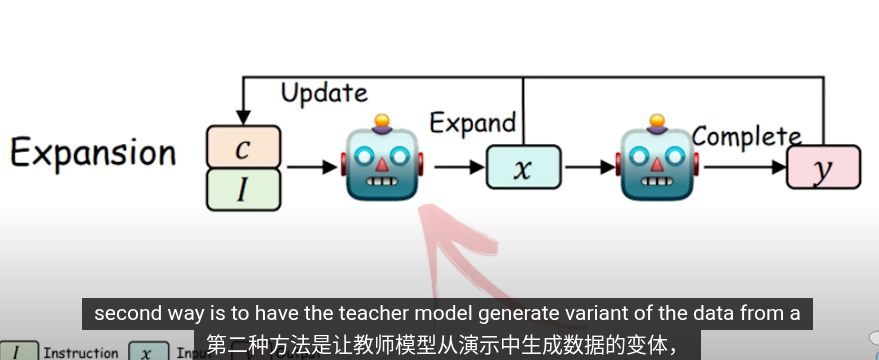
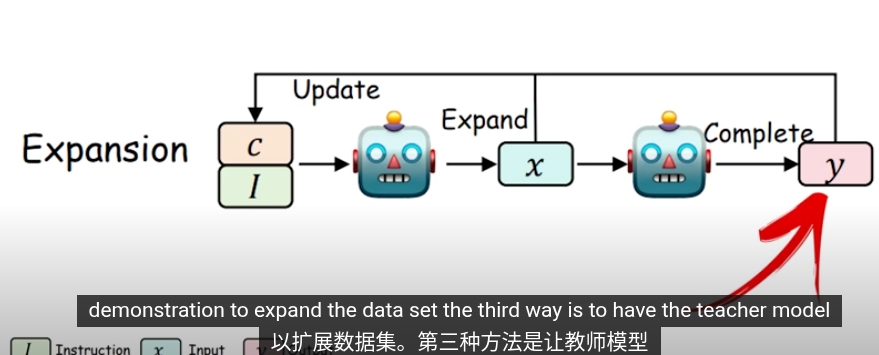
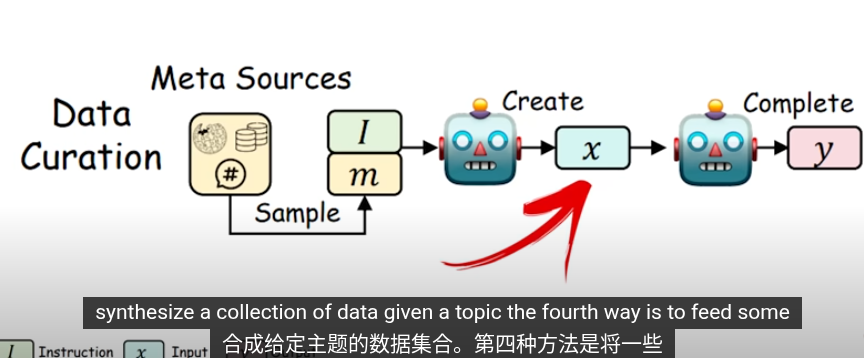
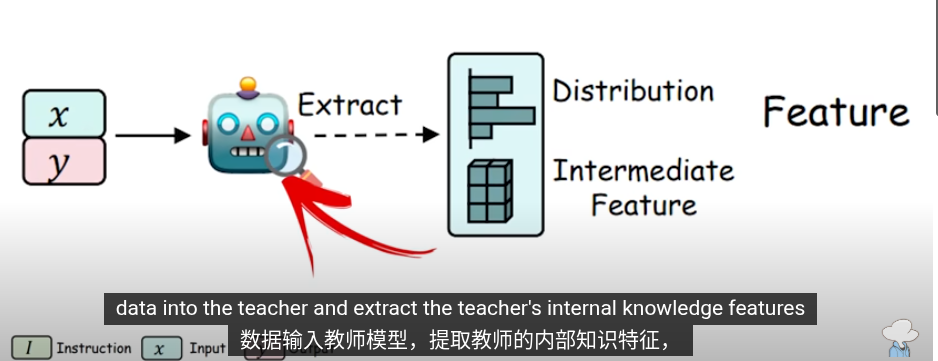
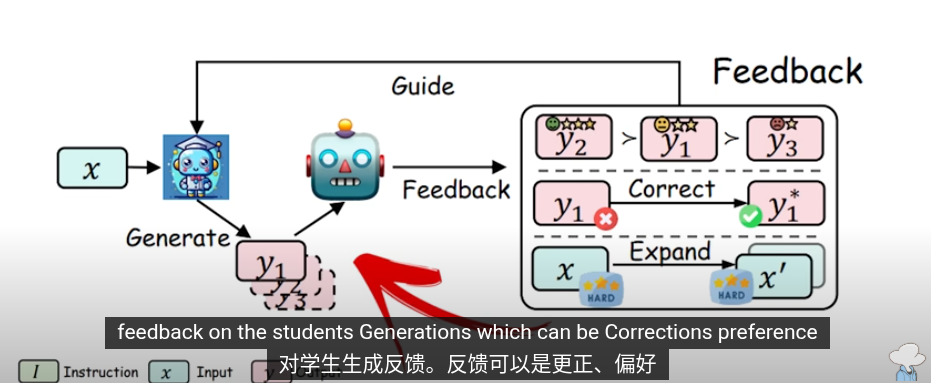
這些是知識提取的方法,把提取的知識用於下一輪的訓練
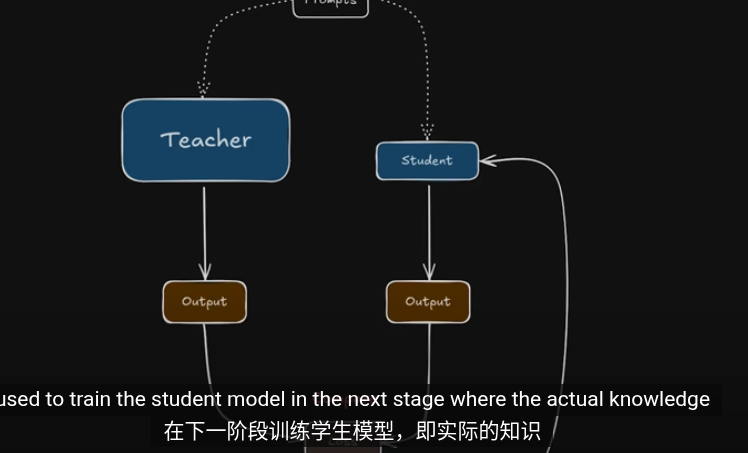






在知識蒸餾,使用交叉商來最小化輸出概率
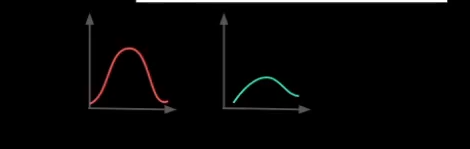
Centering 中心化




DINO
一中新的自監督學習方法







 ====
====
dino 與知識蒸餾的不同之處是


其中教師網絡會與學生一同訓練













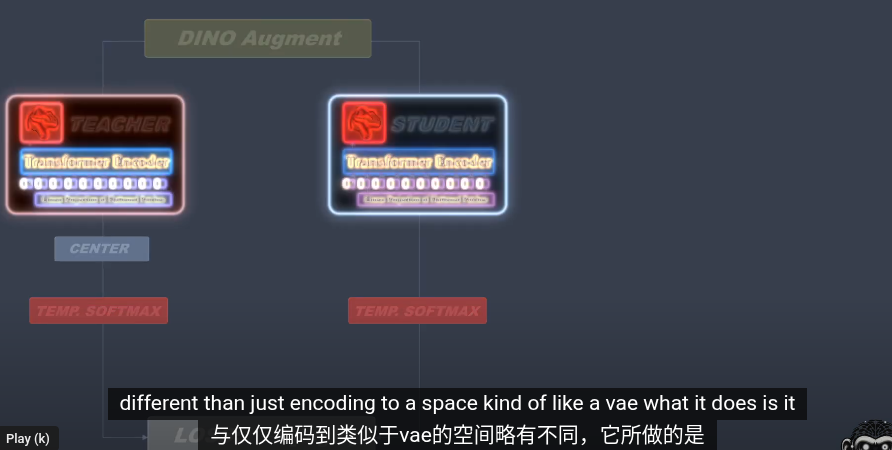

之後使用softmax Tempture


DINOv2 給的溫度是0.07

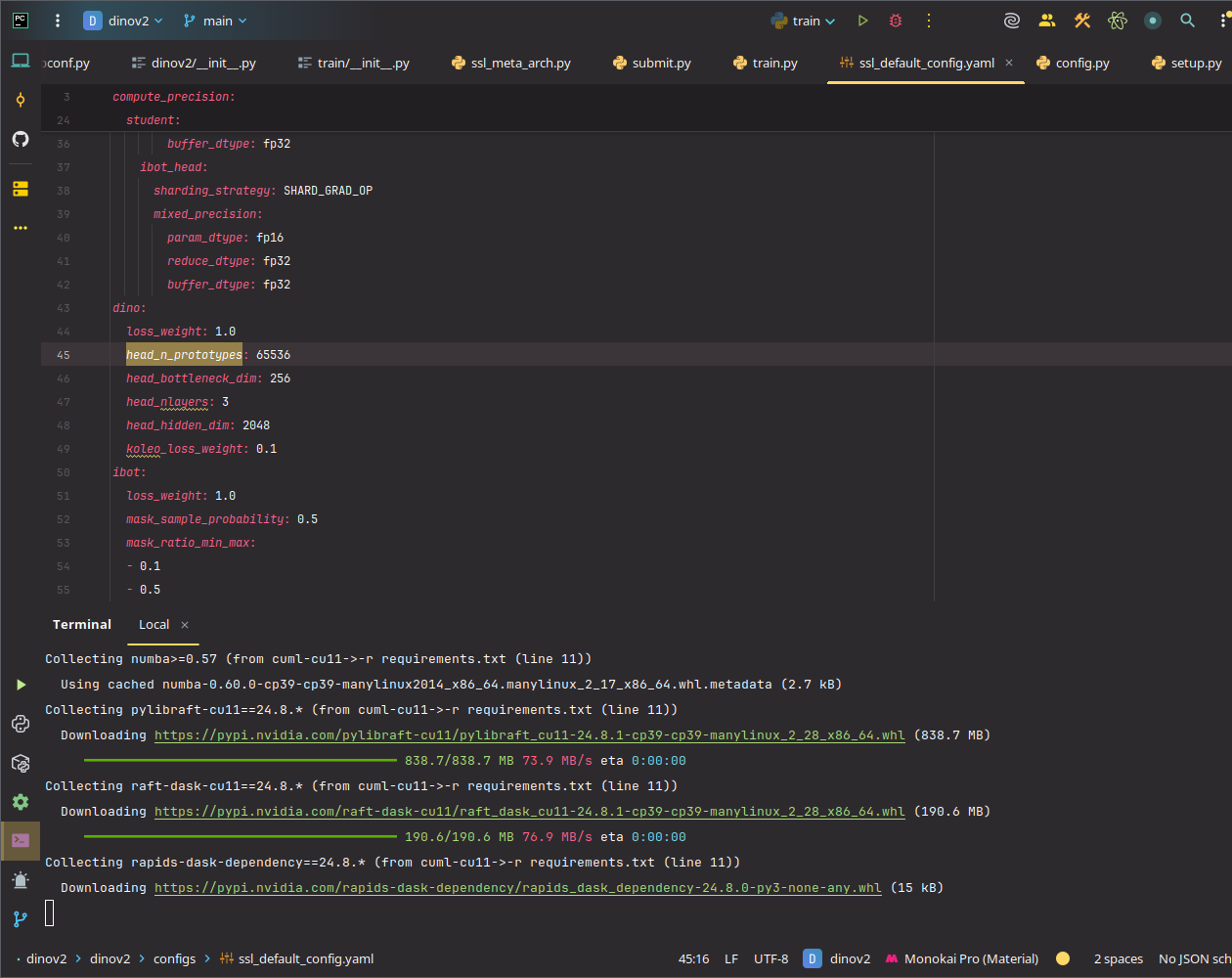
一共有65536類
使用交叉熵來評估兩者輸出

左邊教師 右邊學生

在訓練時,同時更新教師和學生網絡是沒有意義的





DINOv2給的平滑因子是0.992

- EMA
- 數據中心化
- 只傳遞
我們換用

DINOV2
Introduce
想像你有一個二分類分類器,通過softmax後可以得到類別的概率
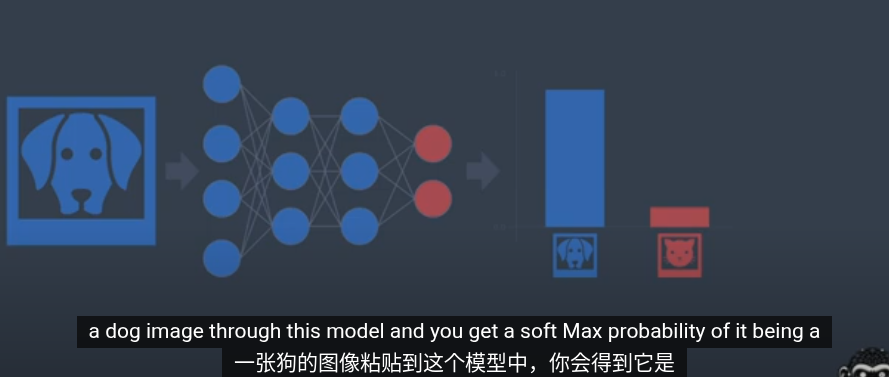
如果我們刪除分類頭

如果加上解碼器,就是VAE

我們假設這是一個3維輸入,那麼圖像會在3爲潛空間中

在latern空間中沿着某個特定方向就可以得到混合輸出
DINO使用了一種不太一樣的方法
